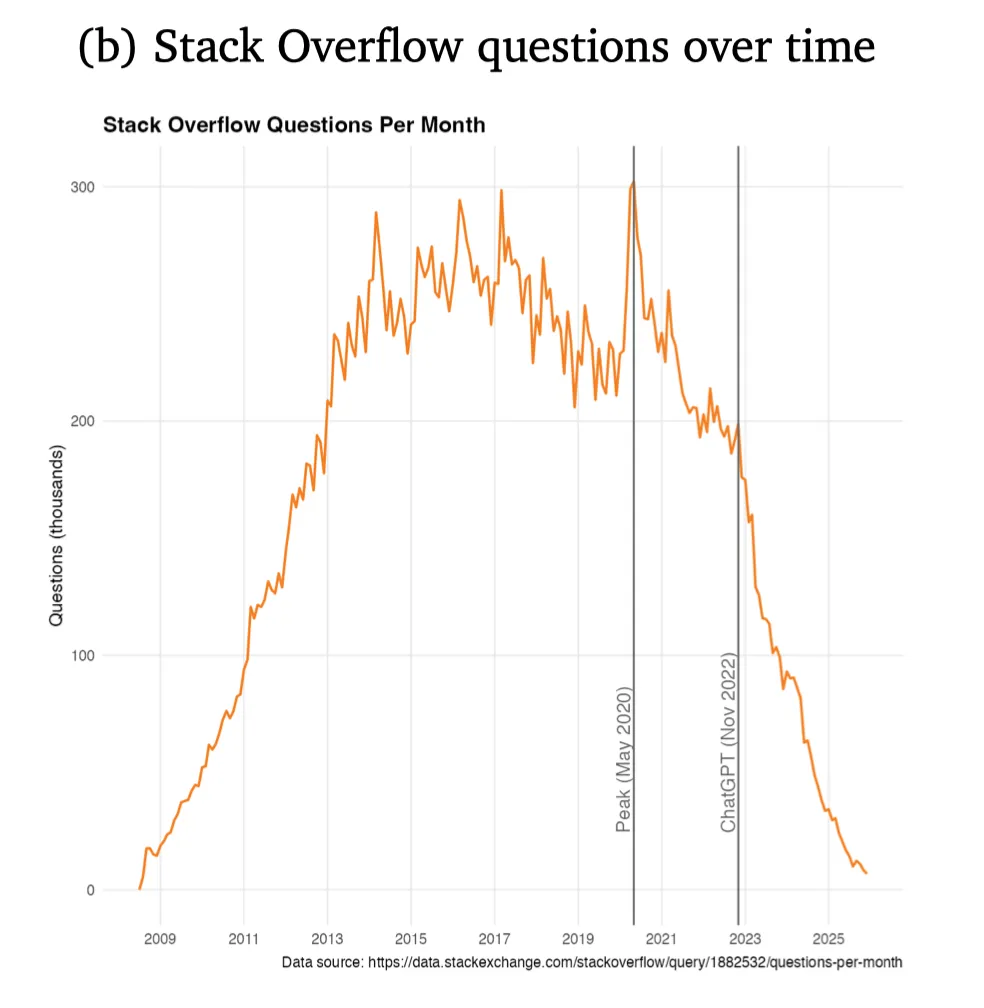
OpenAI 推出全新企业级平台 Frontier
OpenAI 周四发布新的人工智能平台 Frontier,该平台可以帮助公司构建、部署和监督 AI 智能体。
这家 AI 公司表示,Frontier 与 OpenAI 之前发布的 AI 智能体构建工具协同工作,让企业能更轻松地整合智能体执行任务所需的数据源。OpenAI 称,这些智能体将能够处理来自各种来源的信息,并完成处理文件和运行代码等任务。
发布 Frontier 的一个目的,是帮助 OpenAI 吸引更多企业客户。目前,它们正在与 Anthropic、谷歌等对手争夺企业客户。通过将 Frontier 打造成构建和管理 AI 智能体的一种标准,该公司的目标是将更多企业客户带入其整体 AI 生态系统。(来源:新浪财经)

美团 49.8 亿收购叮咚买菜
2 月 5 日,美团在港交所发布公告,宣布以约 7.17 亿美元(约 49.8 亿元人民币)的初始对价,完成对叮咚买菜中国业务 100% 股权的收购。
对于收购原因,美团在公告中表示,公司高度重视食杂零售业务,本次交易符合公司在食杂零售领域的长期发展规划。截至 2025 年 9 月,叮咚买菜在国内共运营超过 1000 个前置仓,月购买用户数超过 700 万。
叮咚买菜创始人梁昌霖也在内部信中表示,对于未来的发展选择放下竞争,转为并肩合作。(来源:第一财经)
蔚来发布盈利预告:预计 2025 年 Q4 调整后利润 7-12 亿
2 月 5 日,蔚来发布盈利预告公告称,根据对本公司未经审计合并管理账目及董事会目前可得资料所作的初步评估,预计本公司于 2025 年第四季度录得经调整经营利润(非公认会计准则),介乎约 7 亿元至 12 亿元。
按公认会计准则,预计蔚来 2025 年第四季度录得经营利润约 2 亿元至 7 亿元。相比之下,2025 年三季度公司净亏损为 34.80 亿元,2024 年四季度净亏损为 71.11 亿元。
这是成立 11 年后,蔚来公司首次有望录得单季度经调整经营利润。
在此前蔚来 2025 年第三季度财报电话会上,李斌表示,除实现计划中的四季度盈利外,公司 2026 年的经营目标是整年盈利。(来源:财联社)
史上首次,米兰冬奥会基于阿里千问打造奥运官方大模型

米兰冬奥会开幕在即。2 月 5 日,国际奥委会主席柯丝蒂·考文垂在国际转播中心举行的活动中宣布,国际奥委会已基于阿里千问大模型打造了奥运史上首个官方大模型。
考文垂在现场高度评价了 AI 技术对本届冬奥会的变革性意义。她表示,得益于千问大模型的技术支撑,2026 米兰冬奥会展现了奥林匹克运动的智能化未来,将成为史上「最智能」的一届奥运会。
目前,这一奥运官方大模型将在专业赛务与公众服务双端同步落地。
在赛务侧,国际奥委会在其面向各国奥委会工作人员的网站上线了「国家奥委会 AI 助手」。该助手依托千问大模型强大的多语言理解能力,并通读数百万字官方手册;在公众侧,国际奥委会也将在官网上线基于千问大模型打造的「奥运 AI 助手」。该助手将面向全球观众开放,通过 AI 技术拉近大众与奥运的距离。(来源:环球网)

传闻 SpaceX 将推出「星链手机」
据路透社报道,在 SpaceX 预计于今年推进 IPO 的背景下,该公司正计划利用其核心营收引擎星链(Starlink)业务进一步拓展市场版图。
知情人士透露,SpaceX 的商业规划不仅局限于卫星互联网连接,更包括推出自主品牌的 Starlink 手机、直连设备服务以及名为 Stargaze 的太空追踪服务。
尽管 SpaceX 此前已与 T-Mobile 建立合作以推进手机直连卫星业务,但在硬件终端制造上,消息源指出马斯克计划打造一款能与现有智能手机直接竞争的移动设备。
针对这一传闻,马斯克近期在社交媒体上回应称「并非不可能」,并强调这款潜在的 Starlink 手机将与传统设备截然不同,其设计将纯粹为了优化「每瓦特最大性能」的神经网络运行,旨在服务于人工智能的算力需求。据悉,SpaceX 已于去年 10 月申请了「Starlink Mobile」商标,并提交了旨在改善小型移动设备连接能力的专利。(来源:凤凰网科技)
小米汽车降低辅助驾驶安全里程门槛
2 月 5 日,小米汽车宣布,最新版本 OTA 已陆续推送,辅助驾驶安全里程门槛降低。据介绍,辅助驾驶安全里程门槛从 1000km 降至 300km,设定这样的门槛,是为了让大家可以先逐步熟悉辅助驾驶功能,培养充分的安全意识。
小米汽车提醒,辅助驾驶不是自动驾驶,请时刻关注路况,及时控制车辆。(来源:每经网)
李想微博发文,预热全新L9:具身智能机器人的开山之作

2 月 5 日,许久不聊车的理想汽车 CEO 李想发布长微博。
李想表示:全新理想 L9,不仅是一台好车,更是具身智能机器人的开山之作,我们准备了十年,就等这一刻。
众所周知,近两年来,李想一直强调 all in AI,那这是否意味着他不再关心汽车了呢?对于这样的观点,他予以了否认。
李想称,「我们深知:具身智能必须长在一台好车上,才能真正为用户创造价值。所以我有 70% 的时间聚焦在汽车上,这让我们更了解如何让车进化成真正的机器人。」
他还表示,即将到来的全新理想 L9,车成为智能体。「眼睛、大脑、心脏、神经、手脚——完整的技术栈让车从被动工具变成主动伙伴。它会认出你,理解你,主动服务你。未来,每个家庭都值得拥有这样的智能伙伴。」(来源:IT之家)

苹果 17e 将于 2 月 19 日发布,新增 MagSafe 依旧单摄

科技媒体 Mac World 近日根据配件制造商流出的消息,推测苹果有望于 2 月 19 日(周四)通过新闻稿形式,发布 iPhone 17e。
此前,苹果通常会选择周一或周二(偶尔周三)发布新品,而 2 月 19 日是周四,有悖于苹果的发布习惯。不过,iPhone 16e 的发布日期也是 2 月 19 日(2025 年)。
改动方面,消息称 iPhone 17e 已配备 MagSafe 磁吸无线充电功能,功率最高可达 25W。相比之下,前代 iPhone 16e 仅支持较慢的 7.5W Qi 无线充电标准,完全缺失 MagSafe 功能。
外观方面,该机背部预计将继续沿用单摄像头设计,屏幕顶部也将保留「刘海」造型(而此前消息称会升级到灵动岛),灵动岛功能可能还需迭代一两代才会下放至 e 系列。(来源:IT之家)
传音 Pova Curve 2 手机亮相:天玑 7100 处理器,6.78 英寸曲面屏

传音宣布将于 2 月 13 日在印度推出 Pova Curve 2 手机。新机采用曲面屏设计,搭载天玑 7100 处理器,配备支持 144Hz 高刷的 6.78 英寸 1.5K 曲面屏,主打轻薄机身和科幻外观。
该机型有银色、黑色和紫色三种颜色可选,其后盖采用四曲面设计的磨砂材质,右下方搭配三角形透明盖板,整体设计延续了上一代的科幻风格。
主要配置方面,传音 Pova Curve 2 搭载天玑 7100 处理器,可选 8GB 和 12GB RAM,提供多种存储组合。机身内置 7750mAh 容量电池,支持 45W 有线快充。
相机方面,该机型配备 5000 万像素主摄和一颗 200 万像素的辅助镜头,前置则采用一颗 1300 万像素摄像头。
系统层面,Pova Curve 2 运行基于 Android 16 定制的 HiOS 16 用户界面。此外,该机型支持光学屏下指纹识别、红外遥控和杜比全景声,机身右侧设置独立 AI 键,整机具备 IP64 防护等级。(来源:IT之家)

美国宇航员获准携带 iPhone 等个人设备记录绕月之旅
美国宇航局(NASA)局长近日在 X 平台发布推文,宣布解除长期存在的禁令,在未来航天任务中允许宇航员携带个人电子设备。
根据多家媒体报道,大部分对此解读为未来宇航员可以携带 iPhone(尚不清楚机型限制)和安卓手机参与航天任务。
在此新规实施前,NASA 对太空摄影器材的认证流程极为繁琐且漫长。艾萨克曼强调,新规的目的是赋予机组人员更便捷的记录工具,让他们能以第一视角捕捉珍贵瞬间,并向世界分享更具感染力的影像。
据科技媒体《Ars Technica》指出,此前预定用于「阿耳忒弥斯 2 号」(Artemis II)载人绕月任务的最新相机是 2016 年发布的尼康单反,随行配备的更是十年前的 GoPro 运动相机。
美国宇航局此前坚持使用老旧技术(如轨道上仍大量使用 G3 PowerPC 处理器),主要是担忧现代电子设备难以通过抗辐射测试。(来源:IT之家)