作者| 桦林舞王
编辑| 靖宇
可能是科技史上最多的一笔融资,出现了。
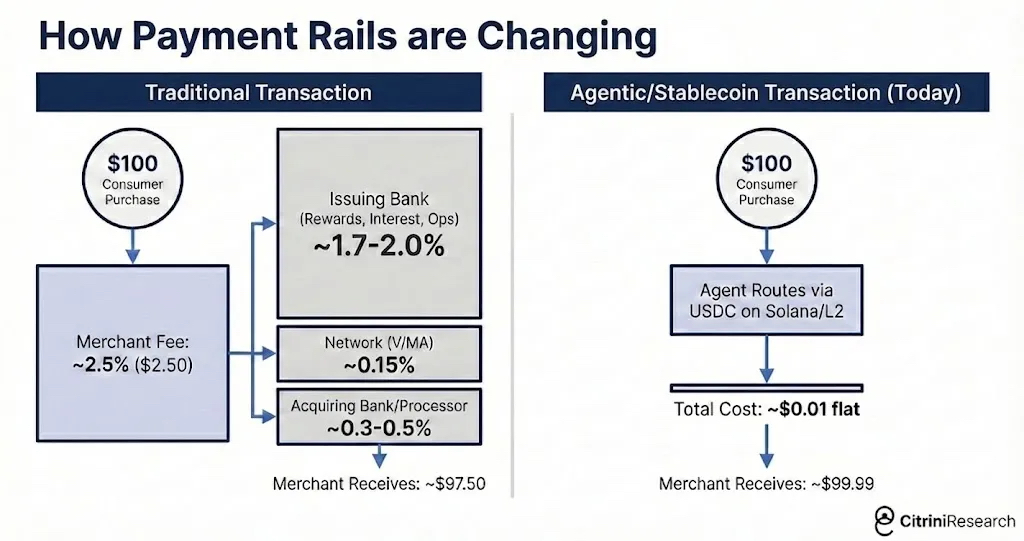
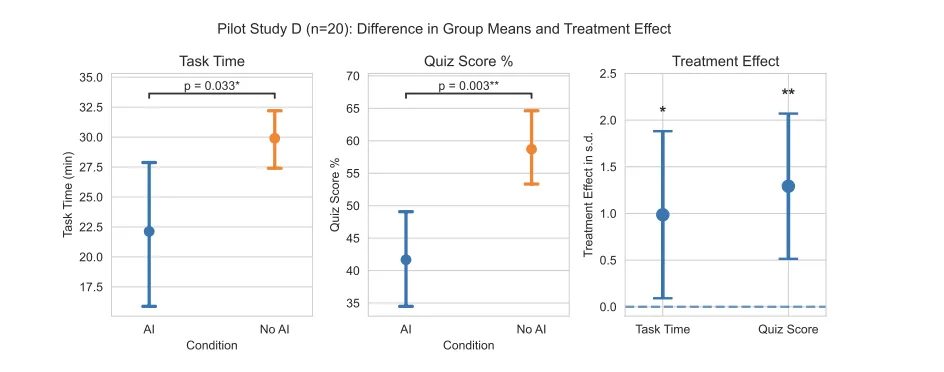
2026 年 2 月 27 日,OpenAI 宣布完成 1100 亿美元融资,估值 7300 亿美元。
这轮融资背后,Amazon 投了 500 亿美元,Nvidia 和软银各投了 300 亿美元。
所有人都在讨论这笔钱有多大、这个估值有多高、这场军备竞赛有多疯狂。但反复看了几遍合同条款之后,我们发现了一件比数字本身更诡异的事:
在这笔交易里,AGI——人工通用智能,这个 AI 领域最核心、最具哲学重量的概念——已经被彻底改造成了一个金融工具。
而且在不同的合同里,它被赋予了完全不同的功能。
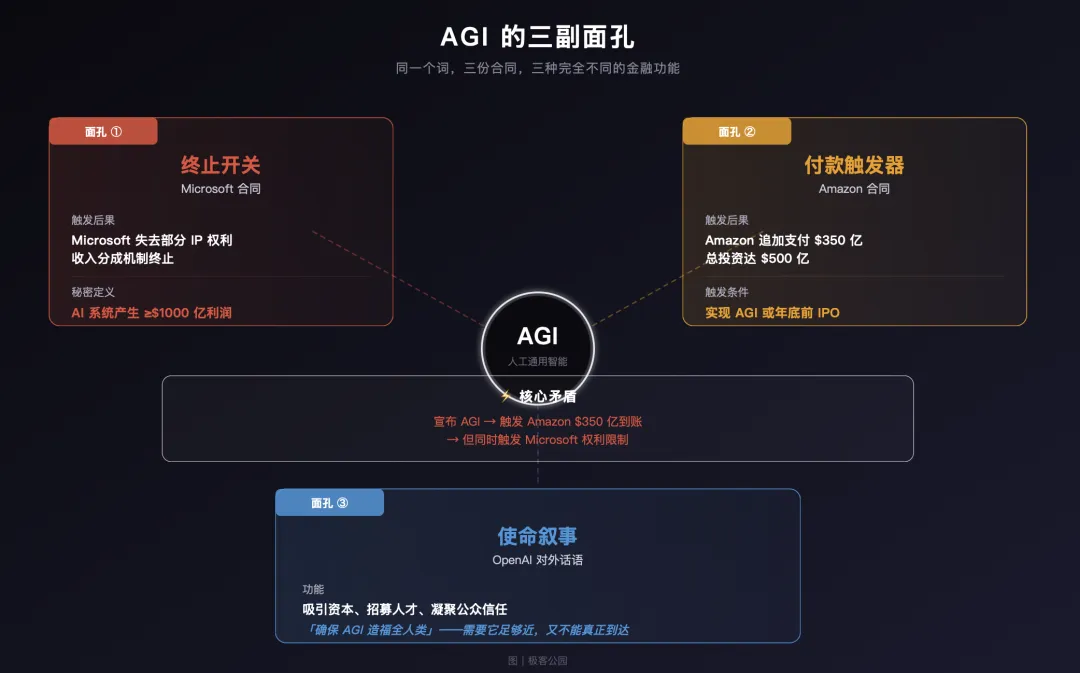
惊人的融资、巨大的理想背后,隐藏着 AGI 的「三副面孔」。
01
AGI 的第一副面孔:利益分配开关
故事要从 2019 年说起。
那年 Microsoft 向 OpenAI 投了第一笔 10 亿美元(此后累计投入超过 130 亿美元),两家公司签了一份在科技史上绝无仅有的合同。合同里有一个条款,后来被称为「AGI 条款」—— 一旦 OpenAI 宣布实现了 AGI,Microsoft 将失去对未来模型的访问权。
这个条款在当时看起来像是一个纯粹的「安全阀」。
OpenAI 的初心是确保 AGI 造福全人类,而不是让任何一家公司独占。所以设计了这道门: 如果真的走到了 AGI 那一步,商业合作到此为止,技术回归「全人类」 。
很浪漫,对吧?
但时间走到 2024 年底,事情变了味。
OpenAI AGI 的三副面孔|图片来源:极客公园
The Information 获取的泄露文件显示,OpenAI 和 Microsoft 之间实际上有一个秘密定义: AGI 的触发条件是—— OpenAI 开发出能产生至少 1000 亿美元利润的 AI 系统。
不是「通过图灵测试」,不是「在所有认知任务上超越人类」,不是任何科学界争论了几十年的标准, 是 1000 亿美元利润。
一个本应由科学家定义的概念,被两家公司悄悄装进了一个财务公式 。(需要说明的是,这一定义出自 2023 年的协议,2025 年 10 月的新协议新增了独立专家验证机制,两套标准目前是否并存,公开信息尚不完全明确。)
2025 年 10 月,双方签了新协议,做了几件关键的事:AGI 的宣布需要由独立专家小组验证;Microsoft 的 IP 权利延长到 2032 年,但 AGI 之后有限制;收入分成在 AGI 被验证之前持续有效。
换句话说, 在 Microsoft 的合同世界里,AGI 是一个「终止开关」——它的功能是:一旦触发,改变两家公司之间的权利和利益分配。
什么时候按下这个开关、由谁来按、按照什么标准按,本身就是一场价值数千亿美元的博弈。
02
AGI 的第二副面孔:付款触发器
现在把目光转向这轮 1100 亿美元融资的主角:Amazon。
Amazon 的 500 亿美元投资并不是一笔买断式的交易。结构是: 先付 150 亿美元,剩下的 350 亿美元需要等「满足特定条件」后才会到账。
The Information 的报道指出,这些条件包括: OpenAI 在年底前实现 IPO,或者达成某个 AGI 里程碑。
看到了吗?同一个词——AGI——出现在了第二份合同里,但功能完全反转了。
在 Microsoft 那边,AGI 是一把悬在头顶的剑:一旦宣布,Microsoft 的权利受到限制。但在 Amazon 这边, AGI 是一张 350 亿美元的支票:一旦宣布,钱就到账。
这两个机制放在一起,创造了一个结构性的荒诞:
宣布 AGI → 触发 Amazon 350 亿到账 → 但同时触发 Microsoft 权利限制
不宣布 AGI → Microsoft 收入分成持续 → 但 Amazon 的 350 亿拿不到
OpenAI 被夹在了两份合同之间。同一个词, 在一份合同里是奖励,在另一份合同里是惩罚 。Sam Altman 需要在两个完全相反的激励之间走钢丝。
当然,还有第三条路:
IPO 。
如果 OpenAI 年底前上市,同样可以触发 Amazon 的 350 亿,而不需要碰 AGI 这个炸弹。
但 IPO 意味着公开市场会对「你到底实现 AGI 没有」这个问题给出自己的定价——到那时,这个问题就不只是两家公司之间的私密博弈了。
更微妙的是交易的另一面。
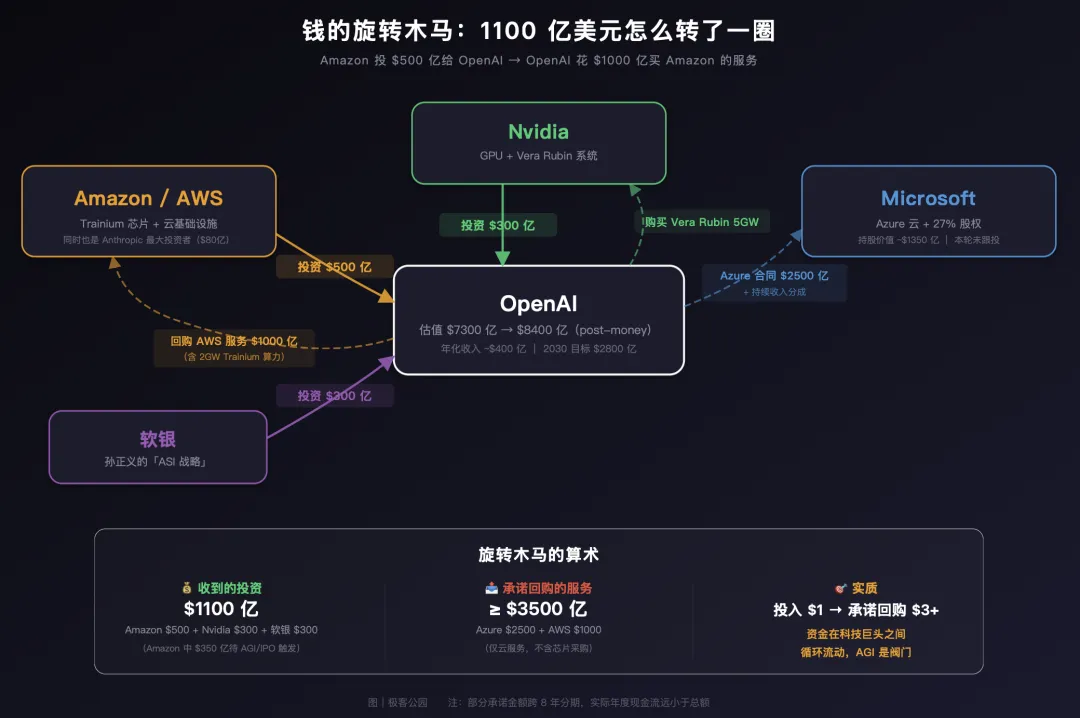
Amazon 投了 500 亿给 OpenAI,但 OpenAI 同时承诺未来 8 年在 AWS 上消费 1000 亿美元,使用 2GW 的 Trainium 芯片算力;此外还将在 Nvidia 的 Vera Rubin 系统上部署 3GW 推理算力和 2GW 训练算力。
OpenAI 天价融资的旋转木马|图片来源:极客公园
Amazon 先给 OpenAI 500 亿,OpenAI 再花 1000 亿买 Amazon 的服务。 资金在两家公司之间转了一圈又回来了,只是中间多了几份合同和一个叫「AGI」的触发器。
华尔街已经有人在喊「圆形融资」了。路透社的分析直接警告:这种企业相互投资并签署供应交易的模式,可能在人为膨胀需求和收入。
但在我看来,「圆形融资」还只是表象。 真正的问题是:当 350 亿美元的现金流挂在一个没有科学共识的概念上,这个概念本身还能保持它的科学含义吗?
03
AGI 的第三副面孔:使命叙事
OpenAI 官网上至今写着那句话:「Our mission is to ensure that artificial general intelligence benefits all of humanity.」( 我们的使命是确保人工通用智能造福全人类 )。
这是 AGI 的第三副面孔—— 它不是合同条款,而是一个「使命」,一面旗帜,一个让投资人写下巨额支票、让顶级研究员加入、让全世界关注的叙事工具 。
Sam Altman 在宣布这轮融资时说:「AI 将无处不在,它正在改变整个经济,世界需要大量的集体计算能力,来满足需求。」而 OpenAI 对外的叙事是:我们正在进入一个新阶段,前沿 AI 正从研究走向全球规模的日常使用。
注意措辞的微妙变化。
两年前,Altman 还在说超级智能可能 2025 年就到来。现在他把 AGI 淡化为「路上的一个里程碑」,说「我们给自己留了一些灵活性,因为我们不知道会发生什么」。
这种姿态调整不是因为技术判断变了——是因为 AGI 在合同里的功能变了。
当 AGI 只是一个学术愿景的时候,你可以大声喊「我们即将实现 AGI」来激励团队、吸引资本。但当 AGI 变成了触发 350 亿美元支付、改变 Microsoft 权利边界、可能引发反垄断审查的合同关键词时, 对这个词的每一次公开表态,都可能产生数百亿美元的财务后果 。
所以 Altman 不得不小心翼翼。他需要 AGI 这个概念足够「近」,近到让投资人相信这场豪赌值得;又需要它足够「远」,远到不会意外触发合同里的地雷。
AGI 在 OpenAI 的对外叙事中,既是终点也是地平线——你永远在朝它走,但永远不能真正到达。 至少在合同条款都安排妥当之前不能。
这让人想到一个更深层的问题。
OpenAI 这轮融资之后,非营利基金会的持股价值超过了 1800 亿美元,号称「史上资源最丰富的非营利组织之一」。
但这个非营利组织的核心使命,恰恰建立在一个已经被彻底金融化的概念之上 。
当「造福全人类」的使命和「触发 350 亿美元」的条款挂在同一个词上时,这个词到底属于科学、资本、还是法务 ?
现在回头看这笔 1100 亿美元的融资,数字本身其实不是最重要的。OpenAI 的估值从 5000 亿涨到 7300 亿,4 个月增长 46%——这些数字会被下一轮更大的融资刷新。
真正重要的是, 这笔交易让我们看到了 AI 行业正在经历的一次深刻转变:最核心的技术概念正在被合同化、金融化、工具化。
AGI 在 Microsoft 的合同里是终止开关,在 Amazon 的合同里是付款触发器,在 OpenAI 的官网上是使命宣言。
三副面孔,三种功能,指向同一个词 。
也许这就是这个时代的隐喻:
一项可能改变人类命运的技术,在它真正到来之前,就已经先被分割、定价、写进了条款 。
科技媒体 Newcomer 对这轮融资有一句一针见血的评论:
「 说服足够多的 CEO 和富人相信你将改变世界,让他们写出巨额支票。 」
问题是——当支票都写完了,AGI 这个词还剩下多少它原本的含义?