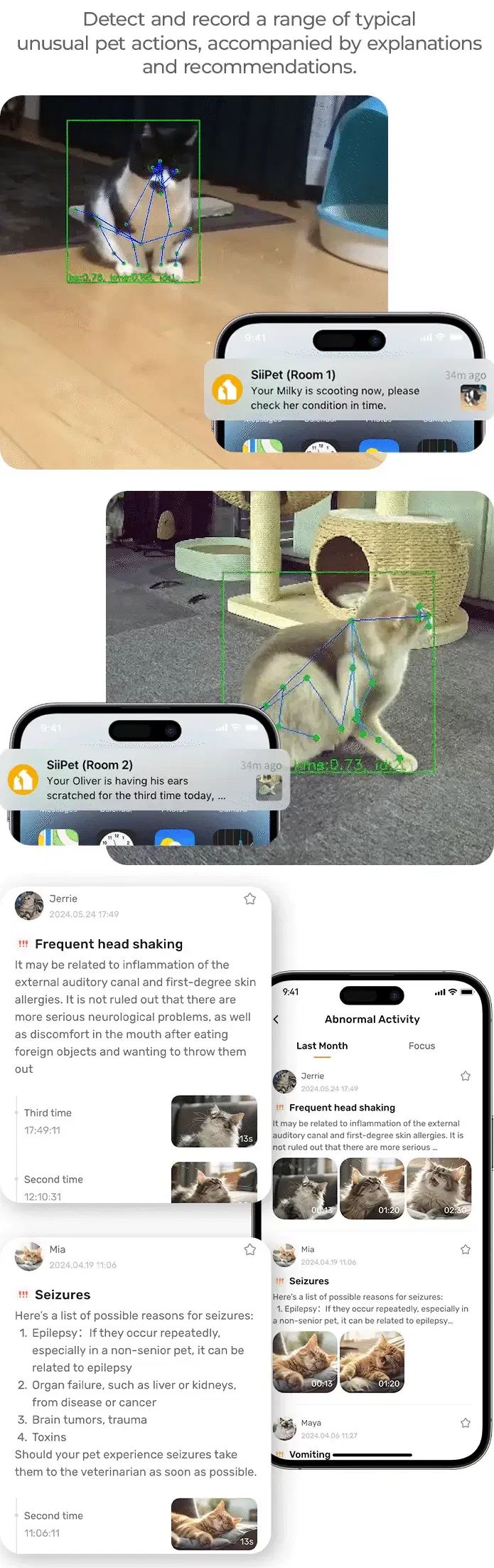
作为众所周知的红海市场,智能手机的销量「触顶」已经是被验证多年的事实,正是在这样的时代背景下,还未开售就已经大放异彩的华为 Mate XT 非凡大师,自然收获了更多的好奇与关注。
销量触顶的智能手机市场,需要更多新鲜空气。而最近大火的华为 Mate XT 非凡大师,凭借着独有的三折叠概念,以及极致科技带来的极致使用体验,走出了一条与让智能手机市场耳目一新的曲线。
即使这是一台起售价 19999 元的超高端旗舰手机 、但在尚未发布前预售量就超过 600 万、9 月 20 日正式开售后更是瞬间售罄。

![]()
三折叠的现象级爆火,背后反映出的是华为 Mate XT 非凡大师作为三折叠手机这一「科技新物种」给用户带来的新鲜感。用户在日复一日的常规形态智能手机迭代中逐渐丧失了换机的兴趣,华为 Mate XT 非凡大师最终呈现出的硬件高水准,让更多用户愿意相信,无论是从功能还是从形态上,都有潜力颠覆现有的智能手机体验。
在华为首发,将三折叠手机从概念带到用户手中背后,其实这个概念也已经伴随折叠屏技术出现多年:每年以 CES 为代表的消费电子科技展会中,都能看到不少三折叠概念机的出现。其中除了以上游屏幕厂商「炫技」为目的的概念机演示,也时有手机厂商参与其中,向外界展示自家在智能手机研发领域的技术积累。
但最终这些都没能真正推向市场,最先拔得头筹的,是华为 Mate XT 非凡大师。
究其原因,从概念机到真正成为量产产品,两者之间的难度有着天壤之别:概念机为了追求极致的震撼效果,往往在其他体验部分有着明显的短板——这些对于概念机来讲无伤大雅,但对量产手机而言,出现任何的细微问题对产品而言都足以致命。
换言之,华为最终成为真正意义上首发三折叠手机的厂商,本身就证明华为在三折叠技术有着深厚的积累,这是比「每年一款概念机」强有力的多的证据。
这幅关于「智能手机的下一次革命」的蓝图,正由华为一点点变成现实。
长期投资「终点再见」
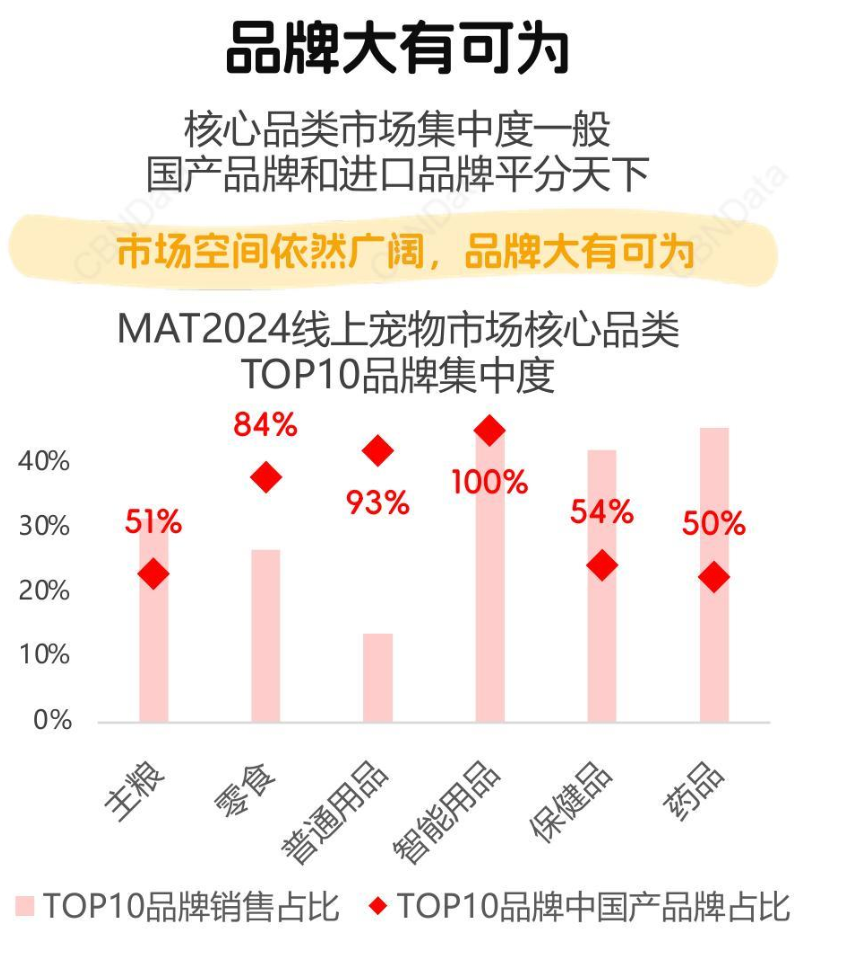
在 9 月 10 日的华为见非凡品牌盛典中,华为消费者业务 CEO、终端 BG 董事长余承东提到华为 Mate XT 非凡大师是华为「五年集大成之作」。

![]()
这里所指的,显然是华为从 2019 年 Mate X 开始,迄今已经发布的、覆盖了外折、内折多种形态的十余款折叠屏手机。
作为在现有智能手机技术之上,对下一代智能手机概念的探索,三折叠从概念到最终量产,显然并非网络上传播的梗图「两个折叠屏拼起来」那样简单,其难度相比传统折叠屏手机来讲甚至可以用「几何倍增加」来形容。
极客公园了解到,在过去五年,三折叠的探索中,屏幕材质仍然是难点最为集中的硬件领域——三折叠在屏幕材质上存在的一大难题,就是柔性屏幕需要做到双向弯折。
在设计屏幕外折结构时,屏幕弯折后位于整机外部,铰链设计需要重点考虑抗拉伸性能;而内折结构时,则需重点考虑抗挤压性能。这两种机械结构在传统折叠屏时代都有数款对应的材料,但却没有一款材料能够同时胜任这两种需求。
面对这种屏幕材料新需求,华为在华为 Mate XT 非凡大师的屏幕上启用了一种采用链状分子结构的多向弯折柔性材料。整体屏幕耐弯折能力提升了 25%,同时也是折叠屏屏幕量产材质首次实现从 -180° 到 +180° 的全向弯折。
三折叠的另一个难点在于铰链。
铰链直接决定了折叠屏的开合手感与使用寿命,在三折叠上,由于加入了屏轴联动设计,为了保证铰链有足以支撑机身的强度,过去三折叠概念机全部采用了厚重的结构,让三折叠概念机难以满足日常使用需求。
而华为则是业内唯一一家、过去五年连续在外折叠转轴技术上坚持投资的厂商,最早可以追溯到华为首款折叠屏手机华为 Mate X。

![]()
在折叠屏技术刚起步的 2019 年,外折相比当时市面上更多手机品牌选择的内折方案,在厚度与重量上都有着明显的优势。但华为最终选择了「技术转向」——华为 Mate X 系列在延续三代后,从华为 Mate X3 开始,变为了当时行业主流的内折设计,外折叠旗舰从此在行业中销声匿迹。
![]()
在华为 Mate XT 非凡大师上,华为凭借着在外折与内折两种完全不同的铰链结构上的技术积累「两条腿走路」,最终实现了三折叠展开厚度仅为 3.6 毫米的惊艳表现,同时攻克了屏轴联动的匹配难题,实现了三折叠上内外开合一致的手感。
原本曾被外界普遍认定是,以及行业内独一份的外折叠鹰翼铰链技术,最终在华为 Mate XT 非凡大师上,以这种方式在终点实现了「再会」。
三折叠,不止于「大」
几乎每一个新物种诞生时,现有用户会下意识将其套入现有的产品使用逻辑中,用现有的习惯去臆想未来;也很容易忽视已经近在眼前、存在巨大潜力的契机。
2007 年,初代 iPhone 发布之后,时任微软总裁史蒂夫·鲍尔默嘲笑「智能手机没有未来」的论据是「它都没有键盘,你甚至不能用它来发邮件」。
就是在这样的嘲讽与质疑广为流传中,智能手机的时代悄然揭开帷幕,十七年转瞬即逝,如今世界上再也没有「带键盘的手机」。
智能手机这一产品形态,本身就是以「变革」立身,随着以全触控操作、应用商店、软件服务优先这些超前于时代的设计,在吸引全球无数用户成为忠实拥趸的同时,也在悄无声息地构建着下一个时代的「基础设施」。
到华为 Mate XT 非凡大师的开售,我们仍不自觉地陷入了「缺乏想象力」的窘境中:想象力匮乏是平庸的开始,众多围绕「三折叠有什么用」为主题的激烈争论,很大程度上是这种深层原因的折射。但也确实说明了华为 Mate XT 非凡大师在抢占先机的同时,也承担着解答这一问题的重要使命。
这个问题的解法,或许可以从五年前找到答案:如今的「三折叠有什么用」在具体解法上,与「折叠屏有什么用」并无太大不同,这一问题随着折叠屏技术被整个智能手机行业携手推动,针对折叠屏探索更多使用场景、开发更多专属功能,最终其「智能手机旗舰产品线」的地位也得到了稳固。
折叠屏在高端旗舰领域所取得的成功,很可能只是折叠屏技术真正大规模给智能手机形态带来改变的前哨战:目前折叠屏的杀手锏功能——应用多开、跨应用全局交互,以及应用多层级窗口同时展示这些操作,很大程度是在将原本 PC 端成熟的软件操作逻辑以更大的屏幕作为平台带到手机上。
在华为 Mate XT 非凡大师发布会中,余承东也展示了为其定制的配套折叠键盘配件,并提出了「将电脑装进口袋」的口号引爆全场,这又是另一次「打破智能终端形态边界」的尝试,把 PC/Pad 装进口袋。
而华为也已经不是第一次「走入无人区」:作为最早布局折叠屏、也是迄今为止唯一量产三种形态折叠屏手机的厂商,华为在折叠屏市场份额已经高达 67%。
在硬件的基础上,华为还拥有能基于硬件深度定制的鸿蒙 OS 操作系统生态:支撑华为以及开发者在华为 Mate XT 非凡大师这一平台上,探索更多独属于三折叠的未来应用场景。![]()
随着三折叠的量产,毫无疑问,如今的华为已经成为了行业内最有资格对「三折叠有什么用」这一问题给出正确答案并将其变为现实的手机品牌之一。
智能手机的未来
诚然,华为 Mate XT 非凡大师在社交媒体的爆火,其核心是超前其他所有手机厂商的三折叠形态。
但在大部分人的注意力都还停留在「三折叠有什么用」这个问题时,我们更不能忽视问题的本质,其实是来自用户的提问「智能手机还会怎样进化」?
比起三折叠在发售后引发的全民讨论,通过三折叠的硬件与软件的持续探索回答好这个问题,或许才是华为 Mate XT 非凡大师对于智能手机接下来注定会到来的形态变革,所能起到的最重要的意义。
智能手机时代即将迈入第三个十年,折叠屏手机作为一个曾被寄予厚望的概念,如今也随着五年的发展,随着三折叠的走向下一个转折点;谁先拿出并量产新形态智能手机,就能享受到最多的先手优势。

![]()
如今,关于智能手机的探索再一次走到了十字路口,三折叠所承载的不仅是「门票」,更像是在搭建舞台本身,以及对外展示华为推动行业变革的决心。
对于行业而言,华为从折叠屏探索高端化之路到三折叠的历程,既代表着智能手机形态的变革,也代表着以华为为首的中国品牌,从竞争者到引领者的变迁。
在这样的时代背景下,华为 Mate XT 非凡大师的登场,率先给出了回答;在智能手机进化的探索之路上,华为已经率先「踏入无人之境」。