作者| 金光浩
编辑| 靖宇
这两天,AI 视频圈被偷摸摸上线的 Seedance 2.0 刷屏了。
在 AI 视频领域颇有影响力的博主海辛,在即刻分享了自己对它的观点:
「Seedance 2.0 是我 26 年来最大的震撼」、「我觉得它碾压 Sora2」。
真的如此吗?一点都不夸张。
这是它做出来的视频,一句话音画同出,几乎无限逼近于影院里看到的电影。
虚拟科幻眼镜幻想视频|视频来源:Seedance 2.0 飞书文档
字节自己在飞书里发了一份产品介绍文档,标题只有几个字,但意味重大:
视频 Seedance 2.0 正式上线!Kill the game(杀死比赛)。
我在 2 月 7 号下午看到了这份文档,出于好奇点进去想快速扫一遍,结果一看就到了晚上。文档右上角显示的同时在线人数, 从下午两点到晚上十二点,几乎没有掉到 300 人以下 。我凌晨四点关掉页面的时候,还有 90 多人同时在线读文档呢(可能是周日的缘故?)。

2 月 8 日凌晨 4 点飞书文档截图|图片来源:飞书文档
一份产品说明文档,被几百人同时围观了十几个小时,我活了三十几年还是第一次见。
我敏锐地意识到: 这可能是一款近期热度堪比 Skills、OpenClaw 的产品。
带着这份好奇,我深度体验了这款模型,看看它到底有什么不一样。
栏目作者召集
极客公园的新栏目「AI 上新」,将带大家体验最新的 AI 应用和硬件,让你成为 AI 时代「最靓的仔」!
现在,我们也向所有喜欢尝鲜和体验 AI 的同学发出召集,只要你发现并体验了新的 AI 应用或者功能,按照格式(参考案例: Kimi K2.5 深度实测:变强了,但待「封神」|AI 上新 ) 向栏目投稿,在极客公园公众号发布,不仅能获得相应稿费,且会为你「报销」AI 应用的订阅费用。
同时, 优秀作者还有机会进入极客公园 AI 体验群 ,获得最新 AI 应用和工具的内测资格,参加极客公园专属相关 AI 活动,和 AI 应用创始人一对一沟通。
AGI 太久,只争朝夕,让一部分人先 AI 起来吧! 投稿、进群请扫描下方二维码添加极客小助手微信

01
Seedance 2.0 做到了什么
先说能力层面。
Seedance 2.0 目前已经在即梦平台上线,会员用户(至少 69 元)可以直接使用。 它支持文本生成视频、图片生成视频,也支持视频和音频作为参考素材输入。简单来说,你能想到的输入方式,它基本都支持了。
但真正让我觉得「这次不一样」的,是它在几个关键能力上的突破。
第一个,自分镜和自运镜。
以前用 AI 生成视频,你需要非常精确地告诉模型「镜头从左向右平移」、「先给一个全景再推到特写」。稍微复杂一点的运镜描述,模型就开始犯迷糊。Seedance 2.0 可以根据你描述的情节自动规划分镜和运镜。你只需要告诉它故事是什么,它自己决定怎么拍。
一段非常简单的提示词,可以生成堪比导演运镜的效果。这也是视频自媒体圈炸锅的重要原因,很多导演引以为傲的「运镜」能力,被 Seedance 2.0 集成到了模型里。比如:
黑衣男子快速逃亡视频|视频来源:Seedance 2.0 飞书文档
第二个,全方位多模态参考。
你可以同时给它最多 9 张图片、3 段视频和 3 段音频,总共 12 个参考文件。这些参考可以用来指定动作、特效、运镜风格、人物外貌、场景氛围甚至声音效果。只要你的提示词写得够清楚,模型基本都能理解你想要什么。这个能力的上限非常高,等于给了用户一个「导演工具箱」。
使用方式:一键 @|图片来源:即梦
第三个,音画同步生成。
Seedance 2.0 在生成视频的同时可以生成匹配的音效和配乐,并且支持口型同步和情绪匹配。角色说话的时候嘴型是对的,表情和语气也能对上。
第四个,多镜头叙事能力。
它可以在多个镜头之间维持角色和场景的一致性。这意味着你可以让它生成一段包含多个镜头切换的完整叙事片段,角色不会从第一个镜头到第三个镜头就换了一张脸。
这四个能力单独拿出来看,每一个都很强。
但放在一起的时候,它们构成了一个质变:
Seedance 2.0 给用户提供的,已经接近「导演级」的控制精度。你不再需要反复抽卡碰运气,你可以真正成为一个专注于讲故事的「导演」。
02
实测:我亲手试了三个场景
能力参数说得再漂亮也是纸上谈兵。我决定自己上手试试,而且故意挑了三个难度递增的场景。
第一个场景,我想生成一个电影感的镜头。
提示词很简单:樱花树下,一个女孩扭头看向一个猫,花瓣飘落,微风吹过她的头发。女孩摸了摸猫的头,对猫说,你好呀,小家伙,最后画面定格在女孩上。
这种画面在 AI 视频里算是「基础题」,但要做好非常考验细节: 花瓣的飘落轨迹要自然,猫的毛发要有质感,风吹头发的动态要连贯,画面的焦距景深要准确。
Seedance 2.0 出的结果让我挺意外。花瓣的飘落有层次感,近处的花瓣大、远处的小,速度也有差异。猫窝在女孩怀里,耳朵偶尔动一下。头发的飘动和花瓣的方向一致,说明模型理解了「风」这个物理条件。整体的色调和光影处理很电影化,不是那种一眼就能看出是 AI 生成的过饱和画面。
同样的提示词放在三天前,无论用什么模型,我可能都需要抽卡十几次才能撞上这个效果。但这次,我一次就出了。
樱花、女孩、猫视频|图片来源:即梦 Seedance2.0
效果很不错,于是继续我加大难度,尝试做一个 15 秒的动漫特效画面。
提示词是这样的:少年主角在战斗中被击倒,在伙伴呼喊声中觉醒隐藏力量。身体周围爆发金色气场,头发变色竖起,眼瞳变为异色。随后以超高速冲向敌人,释放一记巨大的能量斩击,斩击波横切整个天空。
这个提示词信息量很大,包含了情绪转变、特效爆发、动作衔接、画面节奏等多个维度的要求。以前的 AI 视频模型处理这种复杂场景,通常会出现角色变形、特效和动作不同步、画面节奏混乱等问题。
Seedance 2.0 生成的结果,节奏感把控得很好。从被击倒到觉醒有一个明确的情绪转折,金色气场的爆发和头发变色是同步发生的,最后的能量斩击有一个从蓄力到释放的过程,斩击波划过天空的画面确实有燃起来的感觉。
说实话,看到这个结果的时候我脑子里闪过一个念头: 这个效果,已经可以直接放到动漫短视频里用了 。
动漫特效片段视频|图片来源:即梦 Seedance2.0
而当我闪过这个念头,一切就变得很夸张:
我决定做一件以前不太敢想的事,直接用 Seedance 2.0 做一个 60 秒的 AI 动漫短剧。
Seedance 2.0 目前最长支持 15s 的视频,60 秒意味着 4 个 15s,这意味着我们需要多个镜头衔接、角色一致性维持、剧情推进有节奏。放在以前基本上需要借助视频 Agent 工具,把任务拆解成多个步骤,一个镜头一个镜头地生成,再人工剪辑拼接。整个流程下来,做一分钟的内容可能需要大半天。
而由于 Seedance 2.0 可以方便的引用多张图片,我可以非常简单的通过提前生成人物和背景来保证不同视频的一致性。

动漫短剧提示词|图片来源:即梦
于是,我只是分别四次在 Seedance 2.0 里输入了四个只有具体镜头不同的提示词,一段相同的剧情描述,然后再用剪映把他们拼接在一起,就完成了这样的作品:
镜头之间的过渡是连贯的,角色从头到尾没有变脸,情节推进的节奏也很不错,当然由于我只是随意写的提示词,还是有些小瑕疵。
但整个过程我只花了不到 15 分钟,中途没有重新抽过一次卡,效果甚至比某些专门做 AI 视频的 Agent 工具又快又好。
体验到这里,我已经觉得 Seedance 2.0 真的已经杀死比赛了。
动漫短剧片段|图片来源:即梦 Seedance2.0+剪映拼接
03
官方案例:更多能力的展示
但我做的测试毕竟有限。
于是我翻了翻官方放出来的案例,有几个让我印象很深。
一个案例展示了 Seedance 2.0 对于动作的模仿,上传一个视频,和一张动漫图,AI 可以近乎完美的模仿舞蹈动作。这意味着什么?上传一个视频,用 AI 换脸做数字人也是非常简单。
模仿动作、数字人视频|视频来源:Seedance 2.0 飞书文档
有一个案例展示了 Seedance 2.0 的多模态参考能力。创作者同时上传了一张角色设定图作为人物参考、一段视频(含音乐)作为节奏参考,Seedance 2.0 生成的视频中,角色的外貌和设定图高度一致,动作节奏和音乐的节拍也对上了。两种不同模态的参考信息,丝滑的融合到了一个视频输出里。
理解视频里的语音后做的卡点视频|视频来源:Seedance 2.0 飞书文档
还有一个案例可以展示口型同步效果的。

视频制作提示词|视频来源:Seedance 2.0 飞书文档
一段角色对话的视频,角色说中文时嘴型准确,表情跟随语气变化。角色说到激动的台词时,眉毛会上挑,眼神会变得凌厉。这种级别的情绪匹配,在 AI 视频领域之前几乎看不到。
融合提示词后生成的视频|视频来源:Seedance 2.0 飞书文档
另一个案例更直观地展示了多镜头叙事的能力。一段两分钟的短片,包含了远景、中景、特写、跟拍等不同景别的切换,主角从室外走进室内,光线随之变化,衣服上的褶皱和阴影也跟着调整。全程角色一致性没有崩坏。
一镜到底的动漫视频|视频来源:Seedance 2.0 飞书文档
如果你最近多刷视频号、小红书,你会发现官方的案例也只是冰山一角。有很多专业的视频创作者和导演,已经在用它制作「电影」了。
当这些案例放在一起看,你会意识到 Seedance 2.0 已经从「能生成一段视频」进化到了「能拍一部片子」。
04
对视频行业意味着什么
看完产品本身,我更想聊聊它对行业的影响。因为这可能是比产品本身更重要的事情。
第一个冲击,落在视频/漫剧 Agent 身上。
过去几个月,视频/漫剧 Agent 是 AI 视频赛道里为数不多跑通了商业模式的领域。这类公司的赚钱逻辑其实很朴素:一个视频用模型厂商的 API 生成,市场价 50 块钱。漫剧 Agent 公司跟厂商谈年度大单,一年一千万的量,把单价压到 30 块。然后转手卖给用户 45 块。用户觉得比自己去调 API 便宜,Agent 公司中间赚 15 块的差价。
Seedance 2.0 出来之后,这个生意变得微妙了。如果你用其他模型做出来的效果,质量明显比不上 Seedance 2.0。用户一对比就能看出来。但如果你想接入 Seedance 2.0 的能力,你在短期未必能拿到以前那种折扣价,因为所有人都想用上 Seedance 2.0。
漫剧 Agent 以前的价值在于拆解工作流、优化生成流程,用工程手段弥补模型能力的不足。但当模型本身的能力跨过某个门槛之后,工程层面能优化的点就变少了。
很有可能,未来视频/漫剧 Agent 这个赛道里幸存下来的玩家,需要围绕 Seedance 2.0 的模型能力重新设计产品:
未来比的可能就是你对 Seedance 2.0 的理解程度,然后把这套理解做到 Agent 里,这样,你才是有价值的。

字节跳动开发的视频编辑工具将集成 Seedance 2.0|图片来源:X
第二个冲击,来自生成质量的稳定性。
做过 AI 视频的人都知道一个行业内的公开秘密:抽卡成功率。
你让模型生成一段 15 秒的视频,能用的概率是多少?行业平均大概不到 20%。也就是说,你得生成五次以上,才有可能得到一个质量过关的结果。
算一笔账。假设每段 15 秒的视频 API 成本是 5 块钱,做一个 90 分钟的片子,理论成本 1800 块。但实际成本呢?因为 80% 的生成结果要扔掉,真实成本直接翻到了接近一万块。
根据我自己的测试和多位从业者在 X 上的反馈,Seedance 2.0 的可用率直接到了 90% 以上。
这意味着实际成本无限逼近理论成本。 同样是做一个 90 分钟的项目,成本从一万多块直接降到两千多块左右 。省了差不多五分之四,而这种量级的成本压缩,足以改变整个行业的底层逻辑。
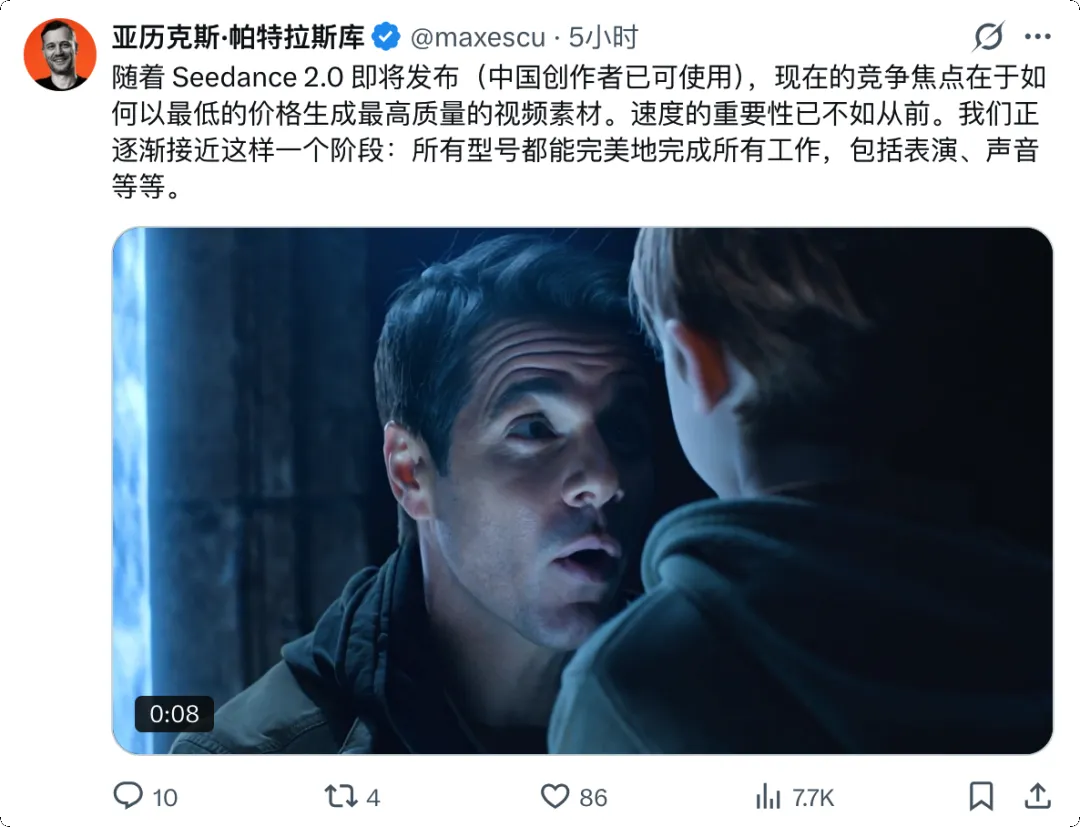
ai_massive 创始人的观点|图片来源:X
第三个冲击,指向了传统影视制作。
一位做了 10 年院线电影的从业者这样评价 Seedance 2.0: 「单从时间和成本来说,已经不是传统流程能比的了。就拿一个特效镜头来说,传统流程下需要一个高级制作人员花将近一个月才能完成,这还不包括其他制作环节」
这样算,如果特效 5s 钟的镜头做一个月,假设工资算 3000 块钱,现在 3 块钱就能在 2 分钟内做完了,这意味着数千倍成本的下降,以及上万倍效率的提升。
短剧领域受到的冲击可能更加直接。短剧的制作成本中,演员、场地、摄像团队占了大头。如果 AI 能够生成足够质量的真人效果视频,这些成本可能被削减 90% 以上。更重要的是,制作周期的缩短意味着你可以快速做 A/B 测试,用数据驱动内容迭代,这是传统拍摄流程完全做不到的。
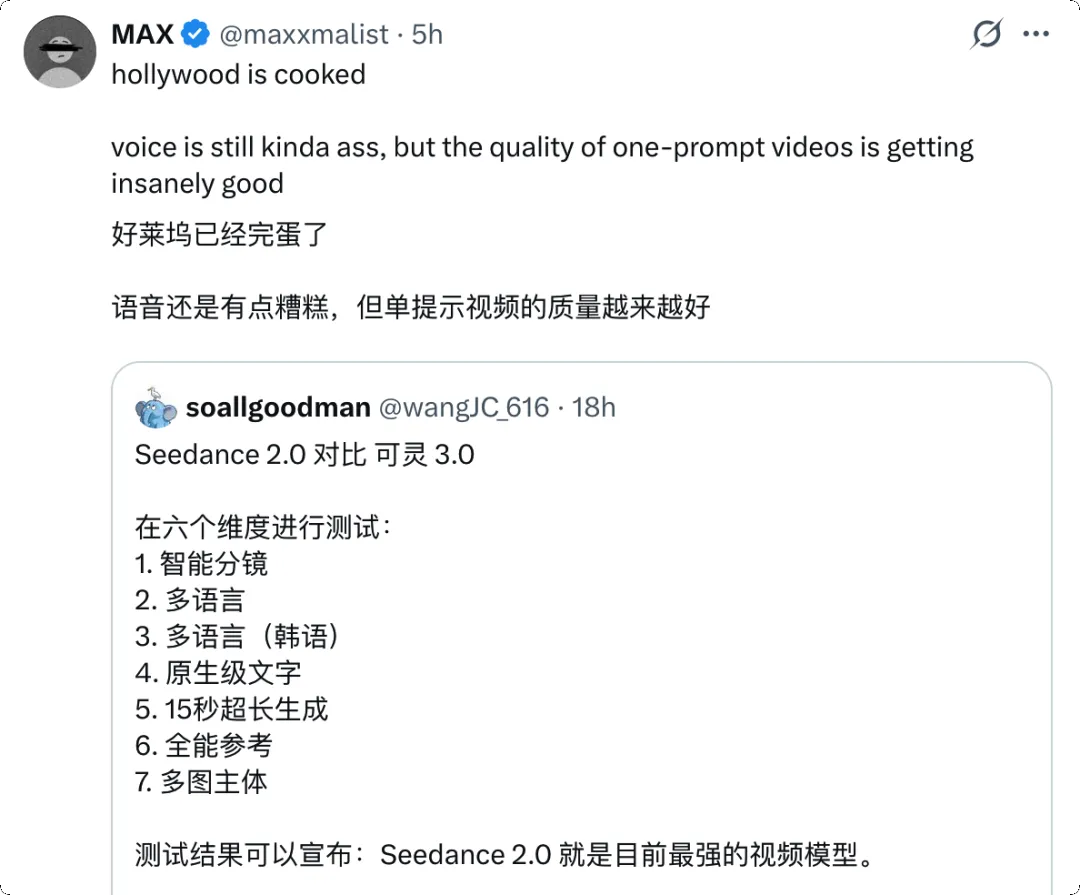
万粉博主观点|图片来源:X
05
第一个「世界模型雏形」的 AI 产品
聊完行业影响,我想说一个可能有些大胆的判断。
我认为 Seedance 2.0 是第一个展现出「世界模型」雏形的视频生成产品。
为什么这么说?
过去的 AI 视频模型,本质上是在做画面补全。你给它一个描述,它从训练数据里找到最接近的视觉模式,拼凑出一段看起来合理的画面。但它并不真正「理解」画面里发生了什么。
Seedance 2.0 在几个关键维度上展现了不同的东西。它能理解物理规律,花瓣飘落的方向和风向一致,物体的重力表现合理。它能理解因果关系,角色觉醒力量之后的气场爆发和后续动作之间有逻辑上的承接。它能理解情绪,对话时的表情和语气匹配,动作的节奏和剧情的紧张程度同步。
它同时消化文字、图片、视频、音频四种模态的信息,并将它们融合成一个连贯的视频输出。 这已经超越了简单的「模式匹配」,开始接近对世界运行规律的某种「理解」。
画面符合物理规律的动漫视频|视频来源:Seedance 2.0 飞书文档
当然,「世界模型」这个词在学术界有更严格的定义,Seedance 2.0 离真正的世界模型还有距离。但从产品体验的角度来看,它已经让用户感受到了一种此前不存在的东西: 模型不只是在「画」你描述的场景,它在「构建」一个有内在逻辑的世界。
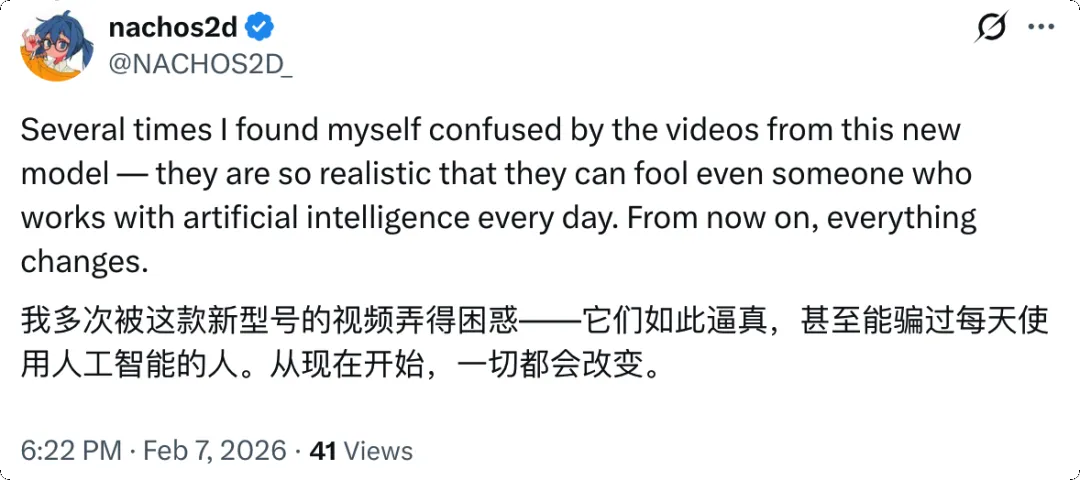
动漫 AI 动画从业者对 Seedance 2.0 的观点|图片来源:X
如果这个判断是对的,那么 AI 视频领域的竞争逻辑会发生一个有意思的转移。
当模型的生成能力足够强、成本足够低、成功率足够高的时候,技术本身不再是瓶颈。你用 Seedance 2.0 能做到的事,理论上别人也能做到。
那什么会成为真正的竞争壁垒?
我觉得答案是两个:好故事和好审美。
技术让「生产」变得民主化了,但「创作」从来不是一个技术问题。知道怎么用工具和知道该创造什么,是完全不同的两件事。当所有人都能用 AI 生成电影级画面的时候,能写出让人看完还想看的故事、能做出让人一眼记住的视觉风格,这些能力会变得前所未有的值钱。
AI 视频赛道的第一阶段,比的是谁能生成更好看的画面、更连贯的动作、更稳定的输出。
Seedance 2.0 把这个阶段的天花板拉得很高,高到大多数竞品短期内够不着,以至于说它杀死了比赛。
第二阶段的比赛已经开始了。
06
好工具,改变思考
回到我测试 Seedance 2.0 的下午,反复生成了大概十几段视频,一个废片都没有,直到现在,我仍然感觉很不可思议。
到后来有一个瞬间,我突然意识到自己思考问题的方式变了。
我不再想「这个模型能不能做到」,而是开始想「我要讲一个什么样的故事」。
这种思维方式的切换,可能比任何技术参数都更能说明问题。
当工具强大到一定程度,它就从你思考的对象变成了你思考的背景。你不会去想「笔好不好用」,你只会想「我要写什么」。
Seedance 2.0 让 AI 视频到达了这个临界点。工具退到了幕后,创作者走到了台前。
如果你也对 AI 视频感兴趣,现在是一个很好的上手时间点,因为此刻的技术已经足够支撑你的大部分创意了。
真正稀缺的,从来都不是工具,是你脑子里那个还没被讲出来的故事。
还有你那独一无二的,对这个世界的独特审美和视角。