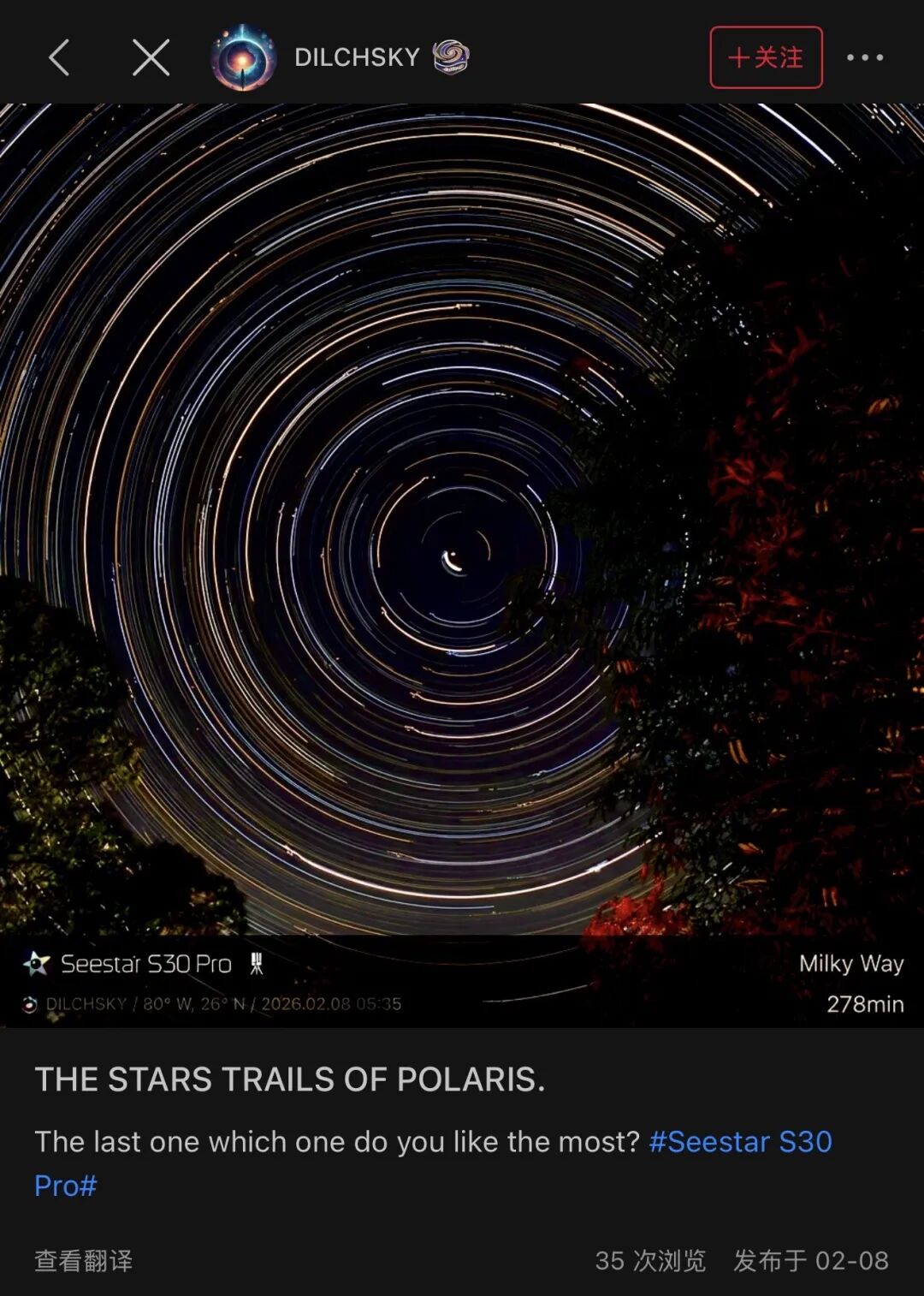
苹果声明仍按计划 2026 年年内推出 AI 版 Siri,股价下跌 4%
2 月 13 日消息,针对彭博社关于「Siri 新功能推迟发布」的报道及随后的股价大跌,苹果公司向 CNBC 发表声明,确认新版 Siri 仍按计划将于 2026 年年内推出。
受该消息影响,苹果公司股价周四下跌 5%,抹去了全年涨势,2026 年下跌近 4%。
苹果公司为稳定投资者信心,随后向 CNBC 发表声明,明确表示公司仍按既定轨道推进,将确保今年(2026 年)发布新版 Siri。不过该媒体指出,苹果的声明更多是在保住「年度交付」的底线,而非反驳具体的版本跳票细节。
一旦正式上线,新版 Siri 有望改变 iPhone 的交互体验,它具备强大的「个人语境」理解能力,支持更丰富的 App 内深度操作。尤为引人注目的是其「屏幕感知」功能,用户可以直接针对屏幕上正在显示的内容提问,Siri 能无缝识别并执行相关的上下文操作,从而解决长期以来语音助手「看不见、听不懂」的痛点。(来源:IT 之家)

原荣耀 CEO 赵明官宣加入千里科技:非常荣幸,一个可以奋斗十年的事业
2 月 12 日消息,原荣耀 CEO 赵明在微博发文宣布:非常荣幸有缘际会千里科技,一个可以奋斗十年的事业,期待与 @ 印奇 兄弟携手一起打造 AI 商业闭环,助力千里腾飞。
千里科技董事长、阶跃星辰董事长印奇发文,对赵明入职表示欢迎:「骐骥驰骋,志在千里!」
早些时候的消息称,吸引赵明加入千里科技的一个重要原因,是已经做了 20 多年手机和通信的他觉得,AI 是下一个值得再投入 20 年的事业——去年 9 月,赵明在一场媒体沟通会上说,「我在寻找能够让我更加兴奋、值得再投入 10 年甚至更久时间去做的事情。」(来源:澎湃新闻)
谷歌宣布 Gemini 3 Deep Think 深度思考大模型升级:推进科学、研究和工程应用,可达数学、物理与化学奥赛金牌水平
2 月 13 日消息,谷歌昨晚宣布对 Gemini 3 Deep Think 进行重大升级,号称是专门针对科学、研究与工程场景的开发的「推理模式」,旨在推动智能前沿发展。
据介绍,新版 Deep Think 由谷歌开发人员与各行业科学家、研究人员共同合作完成,目标是应对真实科研环境中的常见复杂问题:缺少清晰边界、未必存在唯一解,且数据往往杂乱或不完整。
此次升级的一个关键变化是,Deep Think 的可用范围进一步扩大。谷歌称,更新后的 Deep Think 从当地时间 2 月 12 日起在 Gemini 应用中向 Google AI Ultra 订阅用户开放。
在能力表现方面,谷歌强调新版 Deep Think 在数学、算法与编程等高难推理任务上继续提升。该模式在不使用工具的情况下,在终极人类考试(Humanity’s Last Exam)上取得 48.4% 的成绩;在 ARC-AGI-2 上达到 84.6%,并由 ARC Prize Foundation 验证;在 Codeforces 竞赛编程基准上获得 3455 的 Elo;并在 2025 年国际数学奥林匹克竞赛(IMO 2025)上达到金牌水平表现。
除数学与编程之外,谷歌还强调新版 Deep Think 在化学、物理等科学领域同样具备更强能力。官方称,该模式在 2025 年国际物理奥林匹克与国际化学奥林匹克的笔试部分取得金牌级结果,同时在理论物理相关的 CMT-Benchmark 上获得 50.5% 的得分。(来源:网易)
OpenAI 发布 GPT-5.3-Codex-Spark 模型:专为实时编程而生,搭载英伟达竞争对手芯片
2 月 13 日消息,半导体初创公司 Cerebras 与 OpenAI 宣布推出最新的 GPT-5.3-Codex-Spark 模型,主打实时编程。这也是 OpenAI 与 Cerebras 合作的首个公开发布成果。
该模型是其最新代码自动化软件 Codex 的轻量级但更快速版本,旨在与 Alphabet 旗下谷歌及 Anthropic 等公司在 AI 编程助手市场展开竞争。
据介绍,Codex-Spark 主要面向对交互速度要求极高的实时软件开发场景,可实现超 1000 tokens/s 的推理速度,从而实现近乎即时响应的编码反馈。
OpenAI 在公告中指出,近年来「agentic coding」正逐渐改变软件开发方式,机器能够在较少人工监督下持续工作数小时甚至数天。但这种模式也可能带来新的问题,包括开发者等待时间变长、对过程的掌控感降低。
OpenAI 表示,软件开发本质上是迭代过程,需要开发者在过程中不断掌控方向、决定审美与决策,因此 Codex-Spark 被设计为与 Codex 进行实时协作的模型,强调「快速、响应及时、可引导」,让开发者保持在工作中的主导位置。(来源:财联社)
Spotify 宣称 AI 让其开发人员自去年 12 月起未编写过一行代码
据 Spotify 本周在第四季度财报电话会议上披露的信息,该公司最优秀的开发者自去年 12 月以来没有编写过一行代码。这一惊人声明由 Spotify 联席首席执行官古斯塔夫·索德斯特伦姆做出,同时他还阐述了公司如何利用人工智能技术加速产品开发进程。
AI 编码技术似乎已在 Spotify 达到转折点。该音乐流媒体巨头透露,其工程师正在使用一套名为「Honk」的内部系统来提升编码速度和产品开发效率。该系统借助生成式 AI 技术,特别是 Claude Code 工具,实现了远程实时代码部署功能。
索德斯特伦姆在电话会议上举了一个具体例子,展示了这一技术的实际应用场景:”Spotify 的一名工程师在早上通勤途中,可以通过手机上的 Slack 告诉 Claude 修复一个漏洞或为 iOS 应用添加新功能。当 Claude 完成这项工作后,工程师会在手机的 Slack 上收到新版本应用的推送,然后就可以将其合并到生产环境中,这一切都在他们抵达办公室之前完成”。Spotify 认为这套系统”极大地”加速了编码和部署速度。(来源:cnbeta)

小米汽车:能为第一代 SU7 提供至少 10 年备件保障能力
2 月 12 日消息,今天晚间,小米汽车官微发布第 210 集答网友问,其中主要涉及第一代 SU7 停产及新一代 SU7 到店日程等问题。

小米汽车宣布,第一代 SU7 停产后,官方仍会提供和以往一样的全部维修及保养服务。同时,小米汽车为第一代 SU7 准备了充足的配件和供应商生产能力,至少能够满足 10 年的备件保障能力。春节期间,小米汽车服务不打烊。
新一代 SU7 的卡布里蓝实车已在北京小米汽车超级工厂店开始展示,2 月 13 日(IT 之家注:明天)开始将在北京、上海、杭州、广州、深圳、成都、武汉的部分小米汽车商场门店进行展示。小米汽车将尽快提拉进度,在新车上市发布会前将实车陆续送抵更多小米汽车销售门店。待新一代小米 SU7 在 4 月上市后,全国小米汽车销售门店即可提供试驾服务。(来源:搜狐)
启动马达存在缺陷:宝马将全球召回数十万辆汽车,影响 16 款车型
2 月 12 日消息,宝马发言人昨天向法新社证实,由于启动马达存在潜在火灾风险,公司将在全球召回数十万辆汽车。
本次受影响的车型共计 16 款,均配备 2020 年 7 月-2022 年 7 月间生产的启动马达,这些马达的故障原因主要是因为电磁铁会随着时间推移过度磨损发生短路,进而导致启动马达局部过热,最坏的情况下可能导致行驶途中发生车辆起火。
据悉,本次召回将影响全球数十万辆宝马汽车,公司将寄送函件通知车主,让他们尽快更换可能有缺陷的马达。
宝马官方在声明中建议,车主不应在发动机引擎运转的情况下使车辆处于无人看管的状态,尤其是使用远程启动功能时。(来源:新浪财经)
电池存在起火风险,奔驰宣布在美国召回超万辆 EQB 电动汽车
2 月 13 日消息,美国国家公路交通安全管理局(NHTSA)表示,梅赛德斯-奔驰将在美国召回 11895 辆汽车。
IT 之家查询官方公告获悉,此次召回的原因是其高压电池(EB330)可能因内部短路导致热失控和起火风险,影响车型主要为 2022-2024 款 EQB 系列车型。
作为补救措施,梅赛德斯-奔驰将通过经销商免费为用户更换高压电池;监管机构建议车主将车辆停放在室外、远离建筑物,并限制充电。(来源:央视新闻)

索尼 WF-1000XM6 无线耳机正式发布,降噪性能再提升 25%
时隔两年,索尼终于推出了新一代旗舰级无线耳机 WF-1000XM6,作为 WF-1000XM5 的继任者,索尼自信地表示这是迄今为止最出色的耳机产品。在音频处理方面,索尼为 WF-1000XM6 配备了升级版的集成处理器 V2,该处理器现已支持 32 位音频处理,相较于前代的 24 位音频深度有了显著提升。

新耳机采用了继承自头戴式 WH-1000XM6 的 QN3e 降噪芯片,索尼宣称其降噪效果比前代产品提升了 25%,尤其在中高频段表现更为出色。降噪系统配备了自适应降噪优化器,能够实时分析外部噪音,并根据用户的佩戴方式动态调整声音和降噪效果。为了增强降噪能力,升级后的系统新增了两个外向麦克风,使每只耳机的麦克风总数达到四个。索尼还表示,XM6 的环境音模式听起来更加自然逼真。在连接稳定性方面,耳机内部天线的尺寸是 XM5 的 1.5 倍,能够提供更可靠的连接体验。
续航方面,WF-1000XM6 单次充电可提供 8 小时的使用时间,与前代产品保持一致。充电盒可提供两次完整充电,总续航时间达 24 小时。耳机保留了无线充电功能,并具备 IPX4 级防水性能。WF-1000XM6 将推出银色和黑色两种配色,售价为 300 欧元。(来源:cnbeta)

脑虎科技脑机接口技术迭代,首位植入的瘫痪患者可脑控置办年货、写「福」字
2 月 12 日消息,NeuroXess 脑虎科技 2 月 11 日通过公众号宣布,去年 10 月完成国内首例「全植入、全无线、全功能」脑机接口临床植入的患者,通过最新技术迭代,已能独立完成置办年货、书写「福」字、发送红包等日常活动。
据悉,该患者因高位截瘫已卧床八年,通过脑控绘画软件书写「福」字,还能以意念操控手机,在微信群发送新年红包与祝福。

其在术后 1 天即转入普通病房,术后 5 天首次开机成功实现意念操控。经过系统训练,在标准测试中,该患者的脑控解码速率达到 5.2 BPS,与国际顶尖水平相当。
脑虎科技在推文中介绍了其最新研发的 XessKey(随芯控)连接组件。该组件形似普通 U 盘,即插即用,让使用者能够自由选择平板电脑、个人电脑等日常设备进行脑控交互,操作起来如同使用手机一般自然流畅。(来源:IT 之家)