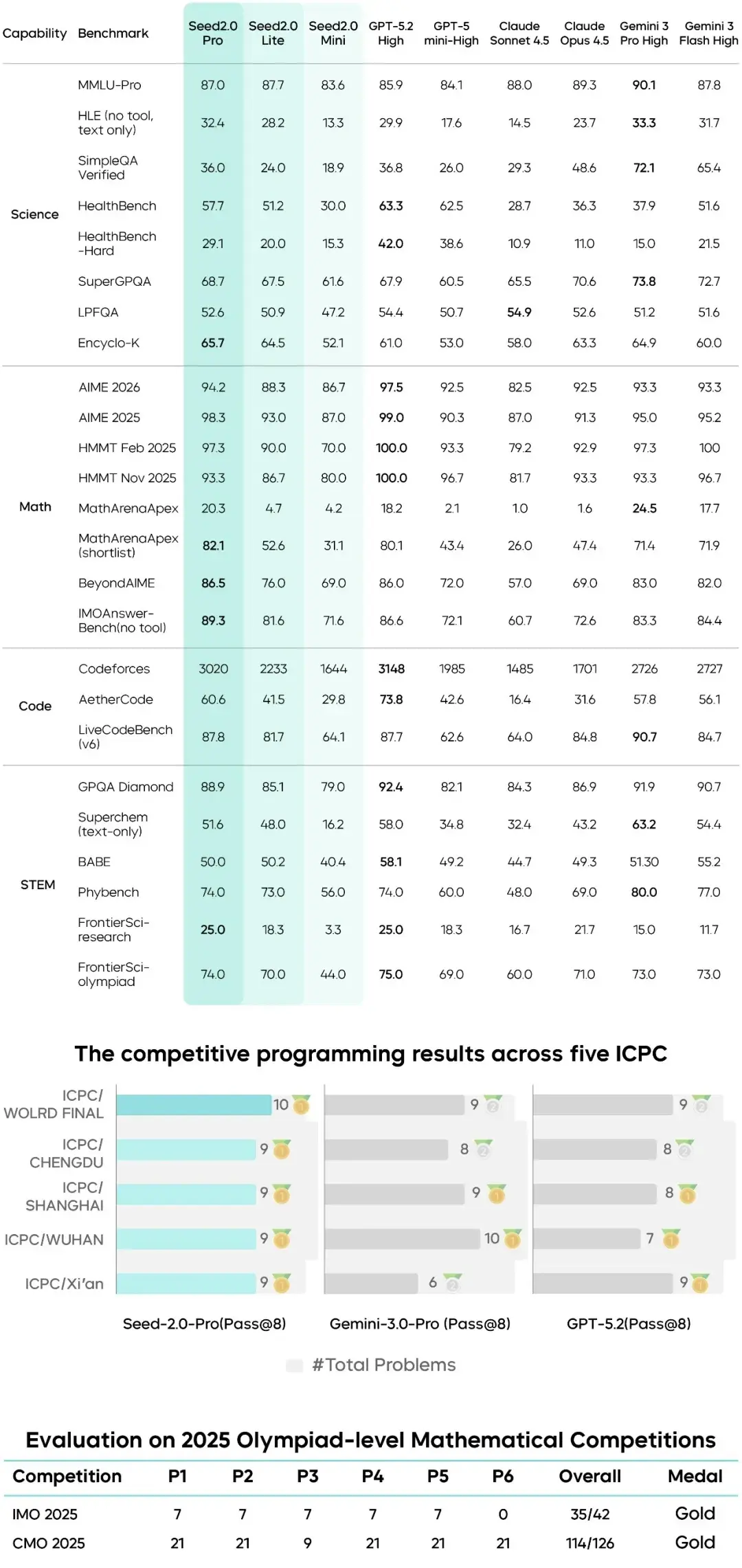
就在刚刚,Anthropic 用一个插件系统,重新解锁了 AI Agent 的新玩法,也将再次「杀死」一批 AI 创企。
2 月 24 日,Anthropic 更新了 Claude Cowork 插件系统,用户可以从零开始定制化打造 AI 插件,将 Claude 能力直接以工具包的方式融入工作流中,打开整个企业级定制化插件市场。
不仅如此,Anthropic 还同步配置了插件创造、使用以及管理的工具平台。Claude 会通过提问,引导用户定制技能、设置相关命令并接入 MCP 协议。所有新增的插件功能都可在新增的自定义菜单中查看、管理。团队和企业管理员还可以直接访问公司配置的插件以及 MCP 控制功能。
目前,Claude 可以接入企业已使用的工具,例如 Slack、Salesforce 和 Excel,Claude 的插件可以在 Cowork 以及任何基于 Claude Agent SDK 构建的系统中运行。所有插件的用户体验更新均面向所有 Cowork 用户开放。
这次,Anthropic 还一口气推出 10 个横跨 HR、运营、设计等领域的官方插件,它不仅是示范 AI 插件玩法,更是在设定标准、圈定企业级 AI 应用的边界。
正当大家开始卷谁的模型更聪明、或者更好用的时,Anthropic 用一套插件系统告诉大家,谁的 Agent 能够以最简单、最直接的方式深入到企业里,才是赢得 Agent 大战中的关键。
一、零基础定制企业级插件,经验即是产品
如果说 Agent 1.0 版本是让一个全知的人担任多面手的不同职位,那么,如今 Claude 则是教公司最有经验的销冠如何零基础搭建适合自家公司的经验包,然后让公司里的每一个人都能用上。
由最懂公司基因的一线员工亲手打造的工具,天然适配自家业务与客户画像,其复用率和提效空间远非外部通用方案可比。这也是 Anthropic 盯上企业私有插件市场的关键原因之一。
目前,用户既可以通过官方模板快速配置相关插件,也可以从零开始深度定制。系统会以对话式引导的方式,通过主动提问协助用户完成技能编排、指令设定与 MCP(模型上下文协议)连接器对接,大幅降低技术门槛。
所有这些配置都会集中在一个名为「自定义」的全新统一菜单中,该菜单整合了插件、技能和连接器,方便个人管理员在一个地方查看和管理所有内容。
企业级管理员还会拥有对企业级的插件更高的控制权,可搭建组织专属的私有化插件市场,对接私有 GitHub 仓库作为插件源,完成更精细化配置与自动化的团队级部署。
不仅如此,插件还和与其他生态应用深度集成。官网显示,Google Workspace(日历、云端硬盘、Gmail)、Salesforce Slack、DocuSign、Apollo、LSEG(伦敦证券交易所集团)、S&P Global 等主流企业工具都已推出适配 Claude 的连接器,甚至不少企业已经为共同客户开发了插件。
除此之外,Claude 本身也实现了跨应用的上下文贯通。它不再仅仅是调用工具,而是可以像人类员工一样在 Excel 与 PowerPoint 之间无缝流转。比如说,它在 Excel 中完成数据分析后,自动将洞察转化为 PowerPoint 演示文稿,保持端到端的上下文连贯性。在用户侧,Claude 的体验也有了更简洁直白的变化,斜杠命令(/command)现在可以通过结构化智能表单呈现,运行「生成报告」或「搭建仪表盘」等复杂工作流时,用户只需填写一份简洁的业务简报。
Claude 还通过新增的 OpenTelemetry 支持,管理员可实时追踪团队对新插件的采用率、工具调用成本及全流程的活动数据,让 AI 投入产出比首次变得可量化、可优化。
目前,Anthropic 已首批上线十大垂直场景的插件模板,从投行交易的智能合规审查,到财富管理的组合分析,再到将资深 HR 的经验编码为自动化新人带教系统。每款都由对应领域的一线从业者参与设计,确保每个 workflow 都基于真实业务痛点,以便更多知识工作者能够充分利用 Cowork 的价值。
新增插件包括:
- 人力资源:简化人事运营流程——招聘、入职、绩效考核、薪酬分析和政策指导。
- 设计:通过生成评论框架、撰写用户体验文案、运行可访问性审核和构建用户研究计划来加速设计工作流程。
- 工程:简化日常工程工作流程,例如编写站会总结、协调事件响应、构建部署清单和起草事后分析报告。
- 运营:管理核心业务运营,包括流程文档、供应商评估、变更请求跟踪和运行手册创建。
- 品牌声音(由 Tribe AI 提供):分析您现有的文档、营销材料和对话,将您的品牌声音提炼成清晰、可执行的准则。
- 财务分析:支持每位财务分析师所需的基本工作流程,从市场和竞争对手研究到财务建模和 PowerPoint 模板创建和质量检查。
- 投资银行:加快交易流程,包括审查交易文件、构建可比公司分析和准备推介材料。
- 股票研究:简化研究工作流程,例如解析盈利报告、根据新的指导意见更新财务模型以及撰写研究报告。
- 私募股权:通过审查大量文件集、提取标准化财务数据、模拟场景以及根据投资标准对机会进行评分,为交易搜寻和尽职调查提供支持。
- 财富管理:帮助顾问分析投资组合,识别偏差和税务风险,并大规模生成再平衡建议。
二、企业级插件的价值被重新定义
此次插件系统更新主要是还是为了能够让 AI 扎入企业深处,将 AI Agent 能力转化为企业的底层基础设施,打通技术与业务之间的壁垒。
通过对话式交互,业务人员得以将个体的领域 know-how 即时封装为可复用的企业数字资产。而模型自动完成的部署编排,则让这种「经验即服务」的能力能够直接为企业业务带来最明显的效率提升。
对于企业来说,定制私有化 AI 插件,会是当下较为简单将组织知识 AI 资产化的方式之一。企业得以最高效的方式,将散落在员工大脑中的隐性经验,转化为组织内的生产力提升。
而且,集中式 AI 定制意味着更少的瓶颈、更快的部署和复用一致的高效工作流程。「我们使用 AI」和「我们依靠 AI 运行」之间的差距正在缩小。
并且,企业还可以通过追踪数据,以结果导向,直接看出定制的 AI 插件是否好用,可以及时调整方向。
事实上,企业级私有插件的本质是专业级代理,而专业级代理将催生更自主的 AI 应用,而Claude 如今将AI生态系统正从模型层向上构建。一旦企业开始构建自己的内部插件,Claude 也开始从一个工具,转向一个平台。 Cowork 显然也不再是一个独立的应用程序,而是现有 AI 技术栈之上的一个集成层,一个工具集装箱。
插件只是当下 Anthropic 先推出的一个基础工具形式。在 Anthropic 看来,插件是最简单的文件系统,可以直接轻量化移动、复用,也是其降低 Agent 走入企业门槛的关键一步。
Anthropic 这一手棋,看似只是新增了一个「技能商店」,实则是向所有只做「功能包装」的 AI 创业公司敲响了警钟。当大模型厂商亲自下场开放「工作流编排权」,那些仅仅把基础 AI 能力打包成简易工具、缺乏深度业务思考的 Agent 产品,将会随时被取代。
这也是为什么此前 Anthropic 推出法律代理时,会引发全球软件和服务类股票 8300 亿美元的抛售潮。

广为流传地有关Claude对软件公司的影响梗图|图片来源:X
尽管Anthropic 企业产品负责人 Scott White 曾对此回应表示,Claude 的目标是为客户带来更好的结果,而不是取代客户。但当「造工具」的门槛被头部公司归零,人人都可以创造产品,创造工具时,「造生态」的窗口正在对初创公司缓缓关闭。