Google 推出 Project Genie:用文本或图片即可生成可交互虚拟世界的 AI 工具
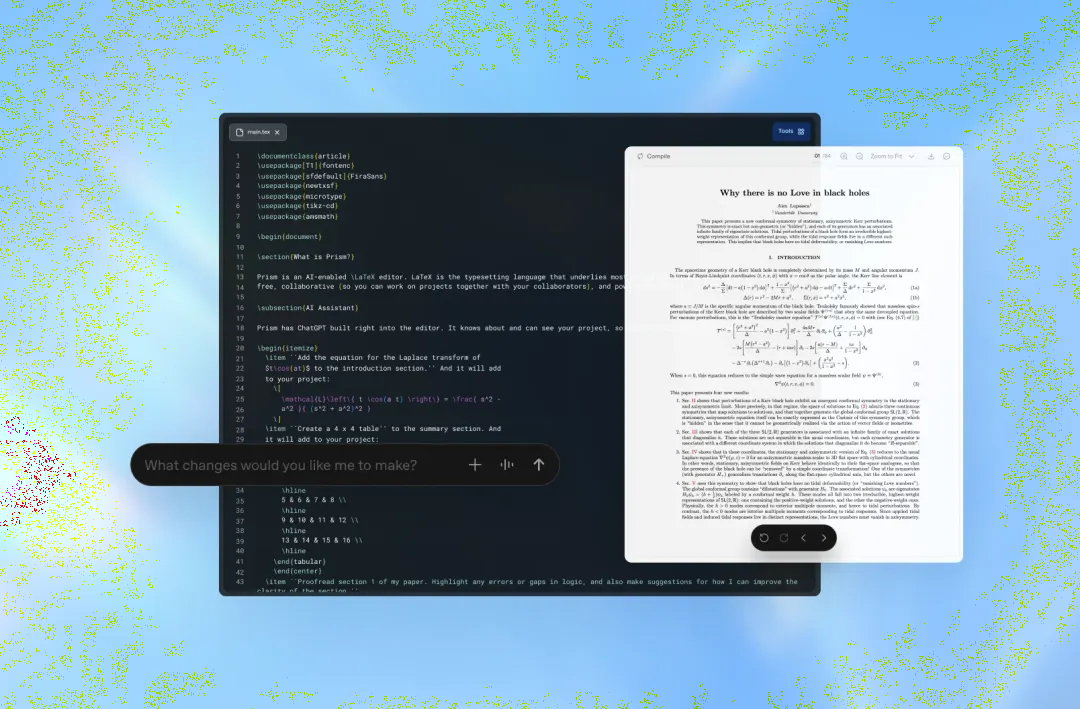
Google DeepMind 正在向部分用户开放一款名为 Project Genie 的全新 AI 模型,用户只需通过文本提示或上传图片,就能即时生成任意风格的虚拟世界,并像玩电子游戏一样操控角色或载具在其中自由探索。这一功能目前通过一款网页应用提供,持有美国地区 Google Ultra 账户且年满 18 岁的用户已经可以尝试使用。
Project Genie 基于 Google 此前在 2025 年 8 月向小范围测试者展示的 Genie 3 模型,同时结合了公司自家的 Nano Banana Pro 图像生成模型以及 Gemini 多模态模型,用于将自然语言提示转化为沉浸式互动场景。用户可以构建的世界类型极为多样,例如操控飞船掠过外星行星、驾驶飞艇飞越上世纪 50 年代风格的欧洲城市,或者让貘在亚马逊雨林深处奔跑等,均可通过简单描述或参考照片快速生成。(来源:今日头条)

库克称 AirPods Pro 3 太火了,苹果始料未及
1 月 30 日消息,路透社布博文,报道称在 2026 财年第 1 财季(截至 2025 年 12 月 27 日)财报电话会议上,苹果首席执行官蒂姆 · 库克(Tim Cook)透露,AirPods Pro 3 自 2025 年 9 月发布以来需求强劲,其火爆程度令苹果「始料未及」。
财报数据显示,「可穿戴、家居及配件」业务类别(涵盖 AirPods、Apple Watch 及 HomePod 等产品)在这一季度营收同比下滑了约 2%。
对此,库克做出了明确解释:这一数据并未反映真实的市场需求,并强调如果不是因为 AirPods Pro 3 遭遇产能掣肘,该业务板块本该在这一季度实现同比增长。(来源:IT 之家)

苹果曾差点为新版 Siri 选择 Anthropic 而非 Google Gemini
彭博社记者马克·古尔曼(Mark Gurman)近日在科技播客节目 TBPN 中爆料称,苹果在为新一代 Siri 选定技术合作伙伴的过程中,原本一度计划「围绕 Claude 重建 Siri」,即采用人工智能公司 Anthropic 开发的大型语言模型和聊天机器人 Claude 作为底层引擎。不过最终,苹果对外宣布,新版 Siri 将转而基于 Google 的 Gemini 平台,这一选择在很大程度上与费用谈判相关。

古尔曼在节目中表示,Anthropic 在谈判中对苹果「狮子大开口」,不仅提出每年需要 Apple Pay 数十亿美元的高额费用,还希望在接下来三年内,每年将这一价格翻倍增长,这被他形容为「把苹果按在了桶底」。在这样的报价压力下,苹果最终放弃了将 Claude 作为面向用户的 Siri 核心方案,转而选择了在定价上更具吸引力的 Google Gemini。
尽管如此,古尔曼透露,Anthropic 依然在苹果的内部体系中扮演着重要角色。据他介绍,目前「苹果在内部很大程度上是跑在 Anthropic 之上的」,Anthropic 为苹果的产品开发和众多内部工具提供支持,苹果还在自家服务器上运行定制版本的 Claude,用于内部使用。(来源:今日头条)
雷军、刘强东等现身 2026 中英企业家委员会会议,小米预计 4 年内在英国开 150 家店面
1 月 30 日消息,据中国日报报道,2026 年 1 月 29 日,2026 中英企业家委员会会议在北京人民大会堂举行。中方企业家代表刘强东、雷军等出席会议。
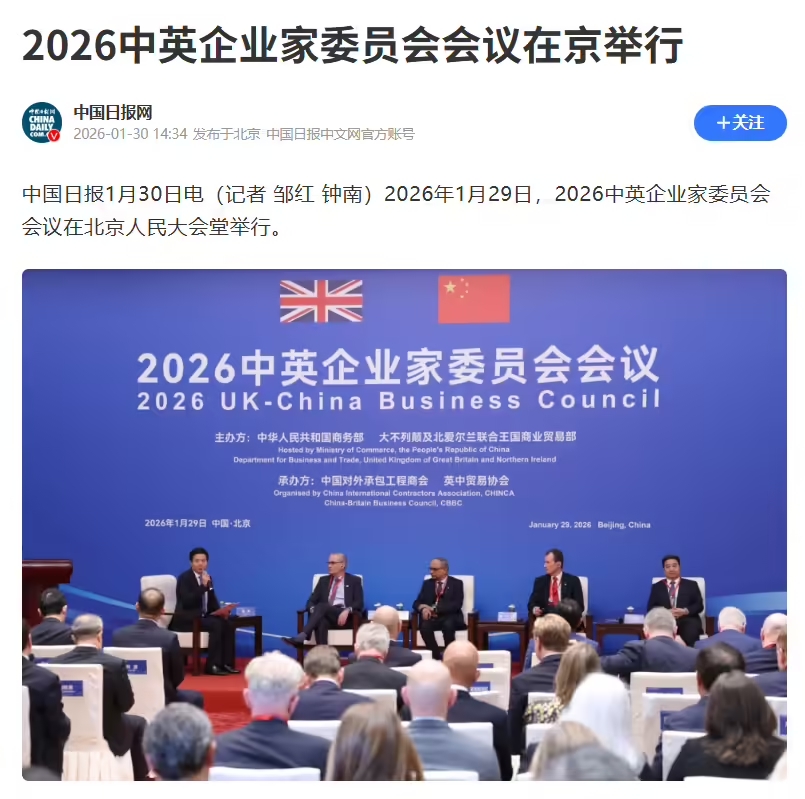
小米创办人、董事长兼 CEO 雷军接受该媒体采访时表示,小米进入英国市场已有几年时间,去年一年大概有 10 亿人民币的收入。如今小米的业务线覆盖全面,从手机到可穿戴设备,再到家电和汽车。下一步计划加大投入,预计在四年之内在英国开 150 家店面。(来源:IT 之家)
腾讯混元再添大将,AI 大牛庞天宇任腾讯混元首席研究科学家
1 月 30 日上午消息,据 MLNLP 社区最新消息,MLNLP 学术委员庞天宇正在招聘 AI 方面人才。庞天宇表示,最近加入腾讯混元,主要研究方向为 多模态模型的强化学习(Multimodal RL),包括生成模型(e.g., diffusion models)和理解模型(e.g., VLMs)。并担任腾讯混元的首席研究科学家和多模态强化学习技术负责人(Principal Research Scientist and Tech Lead of Multimodal RL)。
据悉,庞天宇是清华大学计算机系 2017 级直博生,师从朱军教授。主要研究方向为机器学习,特别是深度学习以及其鲁棒性的研究,取得了一系列的研究成果。他以第一作者(含共同一作)身份在机器学习顶级会议 ICML,NeurlPS,ICLR 上发表多篇文章,并被多次选为 Oral 或 Spotlight.(来源:新浪科技)

曝 iPhone 18 Pro 将首搭星链卫星通信 无需额外硬件实现「无死角」联网
1 月 30 日消息,据 Wccftech 报道,苹果公司正与 SpaceX 深入谈判,计划在其即将发布的 iPhone 18 Pro 系列机型中引入星链(Starlink)近地轨道卫星网络,实现用户无需额外硬件即可直接连接蜂窝网络的功能。
目前,苹果通过与 Globalstar 合作,为 iPhone 用户提供「紧急 SOS」卫星服务,允许用户在无蜂窝网络和 Wi-Fi 覆盖时联系急救部门并共享位置信息。然而,这一功能仅限于紧急场景,且通信内容受限。(来源:环球网)
阿里千问推出新一代 Agent 基准测试 DeepPlanning,已在 Hugging Face 开源
1 月 30 日消息,阿里千问在公众号平台发文,宣布推出新一代 Agent 基准测试 DeepPlanning。

据介绍,DeepPlanning 与传统的推理任务截然不同,要求 AI 在面对现实世界的复杂规划时通盘考虑,不能只专注于局部。
最终实测结果表明,即使是目前顶尖的 GPT-5.2、Claude 4.5、Gemini 以及 Qwen 3 模型,在全局优化以及长周期一致性上仍存在部分短板,距离真正成为拥有 100% 自主决策能力的「行动派」还有一定距离。(来源:IT 之家)

Rogbid 发布二合一智能手表 Rogbid Fusion:50 米防水,可做智能戒指
1 月 30 日消息,Rogbid 推出一款二合一智能手表 Rogbid Fusion,搭载 0.49 英寸 OLED 屏幕,官网目前价格为 49.99 美元(注:现汇率约合 347.35 元人民币)。

Rogbid Fusion 是一款外形小巧、功能齐全的智能手表,尺寸仅为 20.6 x 21 x 8.2 毫米,重量约 14 克,与卡西欧的 G-SHOCK 戒指手表相似。
通过替换附送的表带,Rogbid Fusion 可以在智能戒指和手表间切换形态,其中戒指指环为米兰尼斯风格,手表则为尼龙腕带,表身可选黑色、银色、金色三种配色。(来源:IT 之家)
斑陌易行发布首款智能配送机器人,创始人陈强:国内末端配送场景机器人渗透率不足 1%
1 月 30 日下午消息,斑陌易行近日举行品牌发布会,亮相首款面向具身智能时代的物流配送机器人 (17.380, -0.32, -1.81%) 斑陌易行 T6。秉承「生态开放、高效建设、合作共赢」理念,斑陌易行致力为产业提供一整套场景适配、「乐高式」的产品与技术解决方案。斑陌易行创始人兼 CEO 陈强表示,目前国内已有 200 多家城市开放路权,但末端配送场景机器人渗透率不足 1%。「品牌希望做一些足够务实、足够不一样的工作,助力行业从『单点突破』向『全域协同』升级。」
斑陌易行同期发布技术生态路线,并提出「三步走」规划:首先是工程能力底座的构建,包含无人配送机器人和云端基础平台;其次在算法侧以「车端端到端大模型+云端智能体」为驱动,提升复杂场景下的智能化运营能力;最后,通过 AI 物理形态、场景、地域等维度的拓展,实现产业价值的指数级裂变。此外,帝蛮神(上海)科技有限公司副总裁牛国华、海智蓝图机器人(上海)有限公司 CEO 陈志宝等多家企业代表与斑陌易行现场签约,正式成为战略生态合作伙伴。(来源:新浪科技)


宇树王兴兴:谁能把机器人用的大模型做出来,谁就是全世界最厉害的 AI 和机器人公司,足够拿诺贝尔奖
1 月 30 日消息,《扬声》栏目 1 月 29 日上线了宇树科技创始人兼 CEO 王兴兴的预告访谈。
在本次预告内容中,王兴兴就 AI 与机器人产业的发展方向发表观点。访谈中,王兴兴表示:谁能把机器人用的大模型做出来,谁就是全世界最厉害的 AI 公司和机器人公司,我觉得完全足够拿诺贝尔奖。
王兴兴还坦言:「我们的终极目标,是让机器人真正干活,为人创造实际价值。」
宇树科技曾透露,公司 2025 全年人形机器人实际出货量超 5500 台,2025 年本体量产下线超 6500 台。(来源:IT 之家)