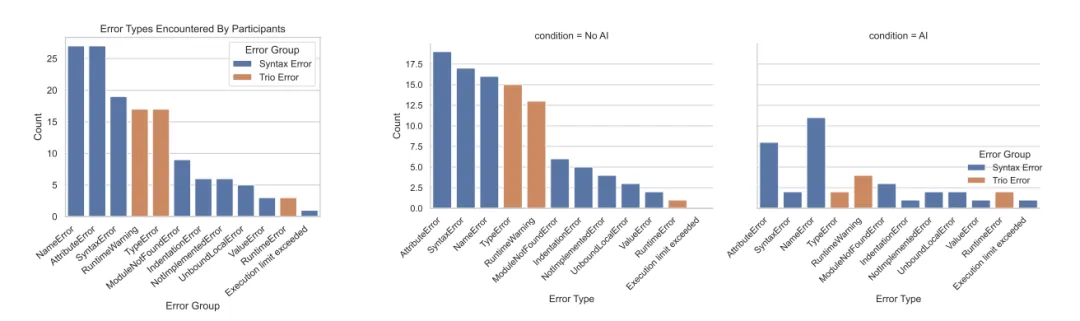
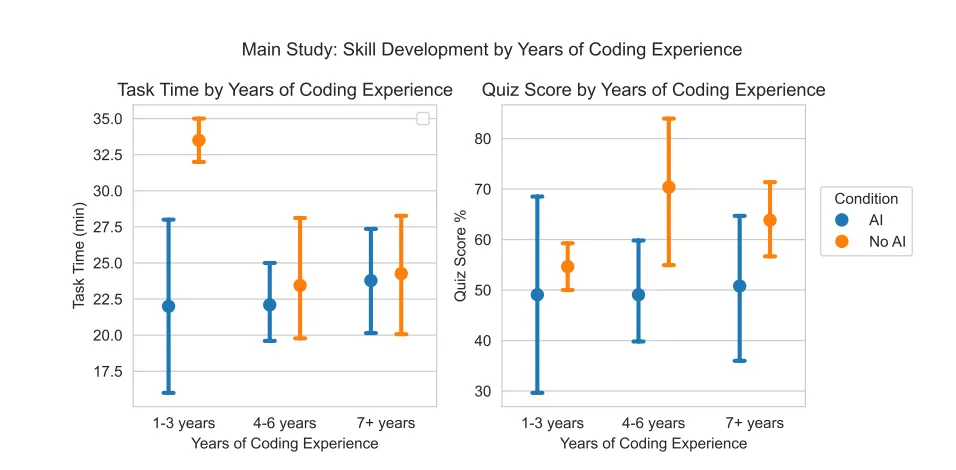
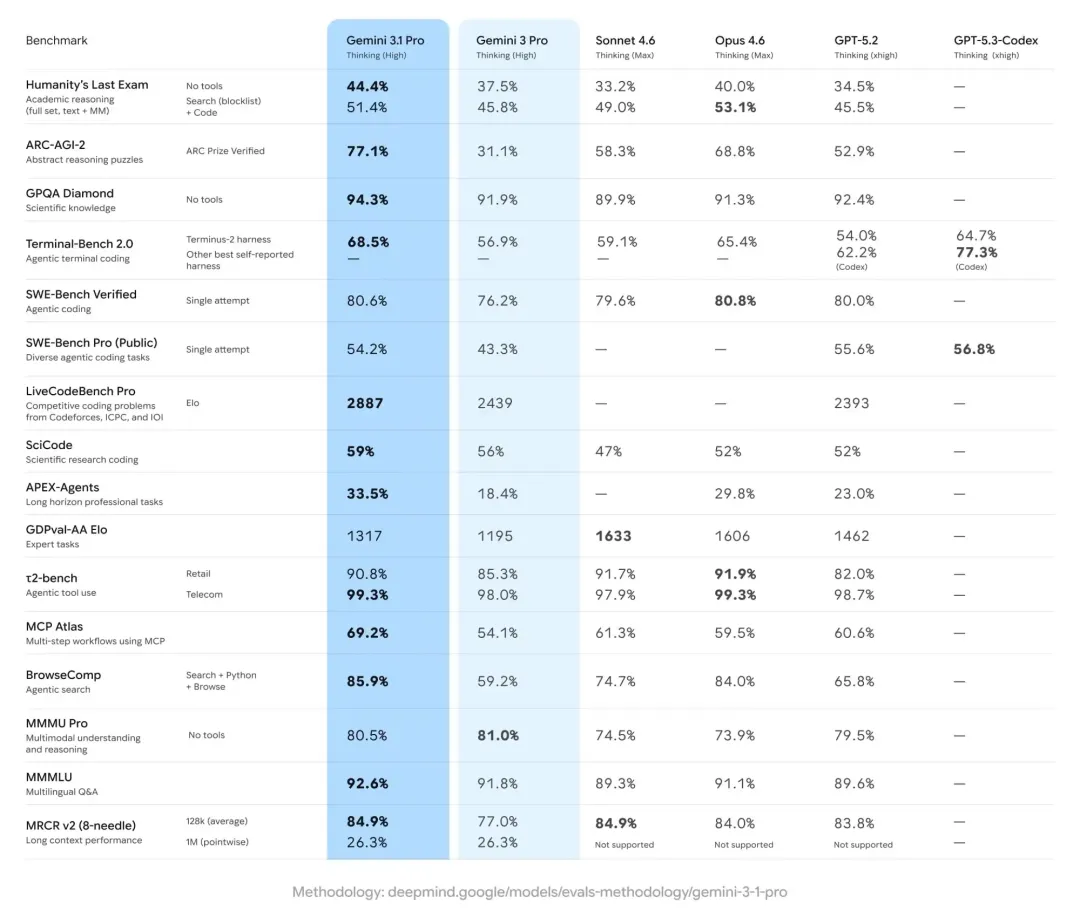
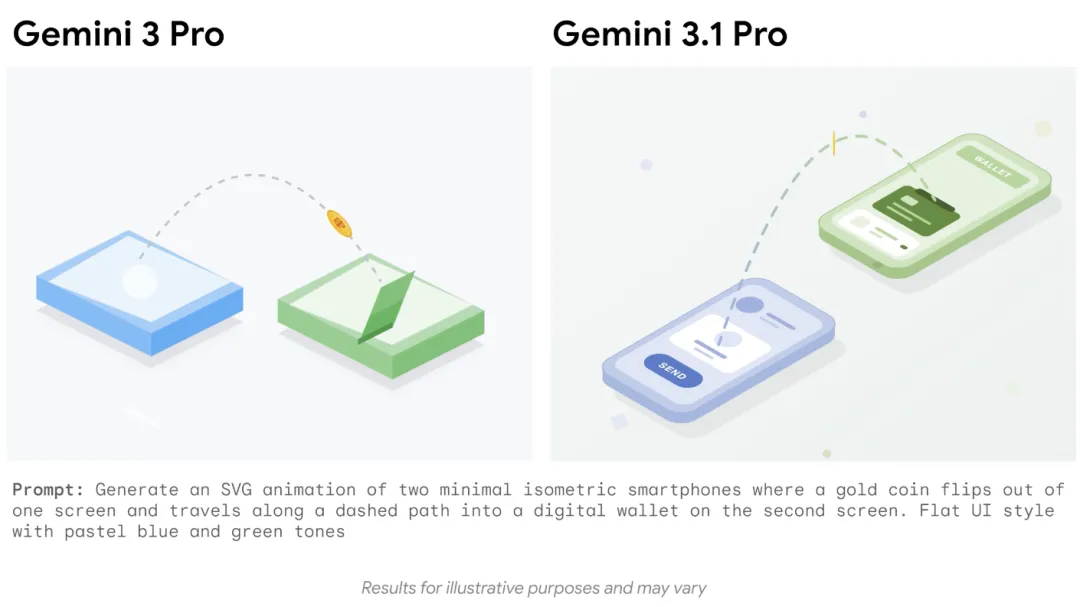
实际上,在全球网友已经玩了两个小时之后,谷歌官方的公告才姗姗来迟,宣布了 Nano Nano 2 的正式到来。
01
三件事,Google 往前推了一步
在接入 Gemini 模型实现网络搜索图像之后,你可以实时地获取世界各地的实时信息来辅助内容生成,比如获取位置以及实时天气数据,来创建逼真的窗户景色。
如果你在 Nano Banana V1 时代就一直在使用它的话,你可能会记得文字渲染一直是个老大难的问题。
这一次,谷歌也终于将其作为一个重要升级项目进行了加强。
02
比起「画得更好」,Google 这次更在意「铺得更广」

03
给创作者的信号:图像模型正在变成「可配置的渲染引擎」
面向开发者/创作者的版本里,还有几个细节值得注意。
Nano Banana 2 新增了 4:1、1:4、8:1、1:8 等超宽幅画幅比例,以及 512px 的低分辨率档。

后者目标很明确:降延迟,适配高并发和快速迭代。它还提供了「可配置的 thinking levels」,分 Minimal(默认)和 High/Dynamic 两档,让开发者在速度与推理强度之间自己拨杆。
如果为了追求极致效果,你当然可以去生成 4K 画质。你甚至可以按照自己的需求、喜好和风格,为自己定制壁纸。

当一个图像模型开始提供分辨率挡位、画幅参数、推理强度拨杆的时候,它就不再是一个「创意工具」,而是一个「渲染引擎」了。 这对两类产品形态会产生直接影响:面向普通用户的模板化出图工具,和面向企业的批量生产系统。
过去靠「套壳 + 流程胶水」建立壁垒的图像工具,接下来的日子可能不太好过。当底层模型自己就能输出结构化、可预测的结果,中间层的价值会被压缩。
另一件事也值得提:Google 在这次发布中继续强化了生成内容的可验证链路——SynthID 水印加 C2PA Content Credentials 的组合。官方透露 Gemini App 里的 SynthID 验证功能已被使用超过 2000 万次。生成式视觉越逼真,验证机制就越得前置,这是一个行业性的基础设施问题,Google 在把它当标配来做。
回到开头的那个问题:图像生成模型的竞争,到底由什么决定?
从 Reuters 此前对 Nano Banana 出圈的报道来看,它确实在短时间内给 Gemini 带来了大量新用户和海量生成量。但「爆款」这种事,偶发性太强。
Nano Banana 2 想做的,恰恰是把偶发性变成确定性:更快、更可控、更容易被调用,铺进尽可能多的产品入口里。它不一定是画得最好的那个模型,但它可能是你「最先碰到」的那个。
在 AI 产品的竞争里,这往往比「最好」更管用。