
从古老的药物到现代的化妆品和药品,药用植物及其多样的用途贯穿其中,而人们对其需求正日益增长。
从古老的药物到现代的化妆品和药品,药用植物及其多样的用途贯穿其中,而人们对其需求正日益增长。

OpenAI 与美国国防部达成合作后,消费端的反应来得又快又直接。
据市场情报机构 Sensor Tower 数据显示,2 月 28 日(周六),ChatGPT 在美国的卸载量环比前一天暴增 295%。过去 30 天,ChatGPT 的日均卸载波动通常在 9% 左右,此次激增幅度远超常态。与此同时,ChatGPT 的下载量也出现下滑。周六当天美国下载量环比下降 13%,周日继续下降 5%。而就在合作消息公布前的周五,ChatGPT 的下载量还曾增长 14%。用户还通过评分表达不满。Sensor Tower 数据显示,周六 ChatGPT 的一星评价数量暴增 775%,周日又翻了一倍。五星评价则在同期下降 50%。
另一边,Anthropic 的 Claude 成为最大受益者。在 Anthropic 宣布无法接受五角大楼的合作条款后,Claude 美国下载量周五环比增长 37%,周六进一步增长 51%。周六当天,Claude 登上美国 App Store 免费应用榜首,截至周一仍稳居第一,较一周前排名提升超过 20 位。
从数据来看,一部分消费者对 AI 公司在军事合作上的立场表现出明确偏好。Anthropic 因拒绝军方条款而获得用户涌入,OpenAI 则因签约而遭遇反弹。AI 产品在消费端的竞争,正在被技术之外的因素深刻影响。(来源:鞭牛士)

刚刚,通义千问核心负责人林俊旸在 X 发文表示将从千问项目 step down。并不一定是离开阿里,但至少意味着千问这条开源旗舰线,进入了一个交棒/换挡的组织节点。
林俊旸年仅 32 岁,是阿里巴巴最年轻的 P10 级技术负责人,也是全球最强开源模型之一——通义千问核心推动者。从北大课堂到达摩院实验室,从算法代码到开源生态,他用十年时间完成了从「让机器懂语言」到「让智能走进世界」的跃迁。
2025 年春,当全行业仍在争论「开源还是闭源」「Agent 还是模型」「具身智能(Embodied Intelligence)是否为下一战场」时,林俊旸已带领团队悄然开启新一轮进化——让智能从虚拟世界走向真实世界,从理解语言到学会行动。
2019 年毕业后,他没有选择学术,而是进入阿里达摩院智能计算实验室,加入仍处于初期的多模态预训练项目 M6。一年后,通义千问立项,他成为核心架构成员;2022 年正式升任技术负责人;2024 年带队开源 Qwen 系列,在全球模型排行榜上与 GPT、Claude 正面交锋;2025 年,他又亲自宣布组建机器人与具身智能团队,试图让模型走出屏幕,去「看世界、动手、行动」。
这次人事调整,讲成为千问的重要分水岭。(来源: ZFinance)
3 月 3 日消息,小米创始人雷军发文宣布,3 月 4 日起,新一代 SU7 实车将陆续进店。预计 3 月中旬,将覆盖全国 143 城 492 店。
目前已公布颜色:卡布里蓝、赤霞红、流金粉、霞光紫、璀璨洋红、雅灰、曜石黑、珍珠白。
新一代小米 SU7 预计在 2026 年 4 月正式上市,上市后,全国小米汽车销售门店即可提供试驾服务。
新一代 SU7 同样提供标准、Pro、Max 三个版本,预售价 22.99 万元、25.99 万元、30.99 万元,相比上一代涨价了 1 万多。
工信部申报信息显示,新一代 SU7 有 73kWh、96.3kWh、101.7kWh 三种规格的电池包,对应 CLTC 工况下九种不同的续航版本,覆盖 630km 至 902km 区间。
具体来看,标准版车型续航由 700km 提升至 720km;Pro 版车型续航从 830km 增长至 902km;Max 版车型续航则由 800km 提升至 835km。新一代 SU7 和现款基本保持一致,前脸格栅中间部分配备了毫米波雷达,标志性的「水滴大灯」远光最远照射距离可达 400 米。(来源:快科技)


3 月 3 日,据韩联社报道,韩国围棋棋手李世石将时隔 10 年再度对战 AI。他曾在 2016 年与 AlphaGo 的人机大战中以 1:4 告负,不过他战胜 AlphaGo 的一局,被誉为人类有史以来第一次战胜 AI 棋手之局。
人工智能创业公司 Infinite 将于 3 月 9 日与李世石合作开展 AI 全球活动。本次对战将在当年对战 AlphaGo 的同一举办地——韩国首尔的四季酒店举行。此外,李世石将亲自登台与 InFuse AI 智能体进行对话,探讨「未来的围棋」,并计划通过实时重构围棋模型来进行对弈。(来源:IT 之家)
3 月 3 日新年阿里开工第一站,马云与阿里、蚂蚁的核心管理层来到杭州云谷学校,与校长、老师们畅谈 AI 带来的挑战和机会。
云谷学校公众号显示,阿里巴巴集团主席蔡崇信、CEO 吴泳铭、风险委员会主席邵晓锋、电商事业群 CEO 蒋凡,蚂蚁集团董事长井贤栋和 CEO 韩歆毅一同参加交流。核心管理层罕见地全部聚齐,体现出阿里巴巴集团和蚂蚁集团对发展 AI 的高度重视。
马云表示,AI 时代已经快速到来,对社会的冲击超出想象,我们大家谁都没有做好足够的准备,但是对十几岁的孩子来说,他们最有改变的希望和机会,所以他就和团队一起来到云谷学校,目的就是把阿里巴巴最近对 AI 越来越清晰的洞察和老师们分享。(来源:新浪科技)

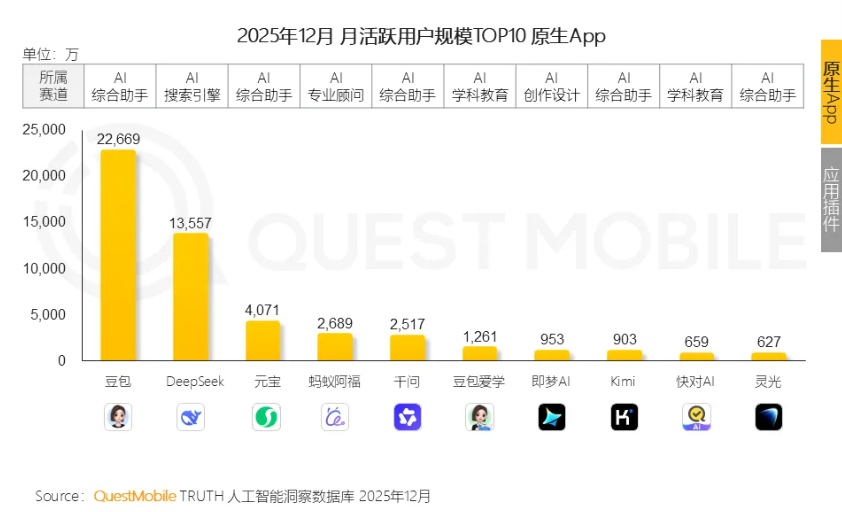
市场调研机构 Quest Mobile 发布《2025 年 AI 应用层发展核心报告》。
数据显示,截止到 2025 年 12 月,移动端 AI 应用月活跃用户规模达到 7.22 亿。具体到 12 月的应用榜单上看,豆包、DeepSeek、元宝、蚂蚁阿福、千问位居前五,活跃用户规模分别达到 2.26 亿、1.35 亿、0.41 亿、0.27 亿、0.25 亿。(来源:新浪科技)

3 月 3 日消息,OPPO 正式宣布新款旗舰折叠屏 Find N6 已在各大电商平台同步上架并开启预约,这款备受期待的年度新品预计将在 3 月份正式与公众见面。
根据官方发布的预热海报,此次发布会不仅将推出 OPPO Find N6 折叠屏手机,还将同台发布全新的 OPPO Watch X3 智能手表,其中集多项新技术于一身的 Find N6 无疑是全场关注的绝对焦点。
在外观设计上,OPPO Find N6 实现了突破性的视觉提升。其屏幕展开后异常平整,视觉上几乎完全感知不到折痕的存在,整机形态如同高端直板手机一般,这一进化标志着折叠屏手机正式迈入无痕时代。
为了达成这种极致的平整度,该机首发了无痕钛合金铰链以及自修复记忆玻璃。通过全新的铰链结构设计,手机在折叠过程中产生的物理应力得到了有效分散,从根源上减轻了折痕的产生。
与此同时,自修复记忆玻璃能够在屏幕展开后快速引导表面恢复至平整状态。在两大核心技术的共同加持下,OPPO Find N6 成功通过了德国莱茵的严格测试,被认证为目前全球最平整的折叠屏手机。(来源:快科技)

3 月 3 日消息,今日晚间,苹果官网正式上架了全新的 MacBook Pro 系列,起售价定为 17999 元。这款备受期待的生产力工具将于 3 月 4 日开启预购,并计划在 3 月 11 日正式开卖。
此次新品最核心的亮点是首发搭载了 M5 Pro 和 M5 Max 芯片。新机提供了深空灰色与银色两款经典配色,尺寸上依然延续了 14 英寸和 16 英寸两种选择,以满足不同专业用户的便携与显示需求。
具体的售价分布方面,14 英寸型号的 M5 Pro 版本起售价为 17999 元,而搭载更强性能 M5 Max 芯片的版本则由 29999 元起步。
对于追求更大显示空间的用户,16 英寸 MacBook Pro 也给出了明确的价位。其中 M5 Pro 版起售价为 21999 元,顶级的 M5 Max 版起售价则达到了 31999 元。
作为苹果目前最强的笔记本电脑,M5 Pro 芯片最高配备了 18 核中央处理器以及 20 核图形处理器。得益于第三代光线追踪引擎的加入,它的 3D 建模能力更加精细清晰,能够轻松应对各类专业应用和重度游戏。(来源:快科技)


随着人工智能数据中心需求的持续激增,美国正遭遇严重的电工短缺危机,这一问题不仅拖慢了建设进度,更对该国经济增长构成潜在威胁。
根据国际电工工会(IBEW)的报告,未来十年内,美国预计需要超过 30 万名新电工来满足这些需求。当前美国电工人力结构面临严重老化困境,近 30% 的工会电工年龄介于 50 至 70 岁之间,每年约有 2 万名电工退休,新旧力量衔接断层,让新一代电工成为市场迫切需求。
与此同时,数据中心建设正迎来爆发式增长,麦肯锡预测,到 2030 年全球数据中心的投资可能达到 6.7 万亿美元,掀起前所未有的建设热潮,一座大型数据中心建设高峰期需动用 1500 名工人,进一步加剧了劳动力市场的压力。
目前美国许多地区的电工工资已经达到每小时 59.5 美元,年薪超过 12 万美元,按当前汇率折算,折合人民币超过 82 万元。
面对电工短缺难题,谷歌、微软等科技巨头已率先行动,纷纷投资于当地的劳动力培训计划,与电工培训机构展开合作,致力于拓宽电工的培训渠道,全力保障未来数据中心建设所需的电工人力供应,缓解行业缺口。(来源:快科技)