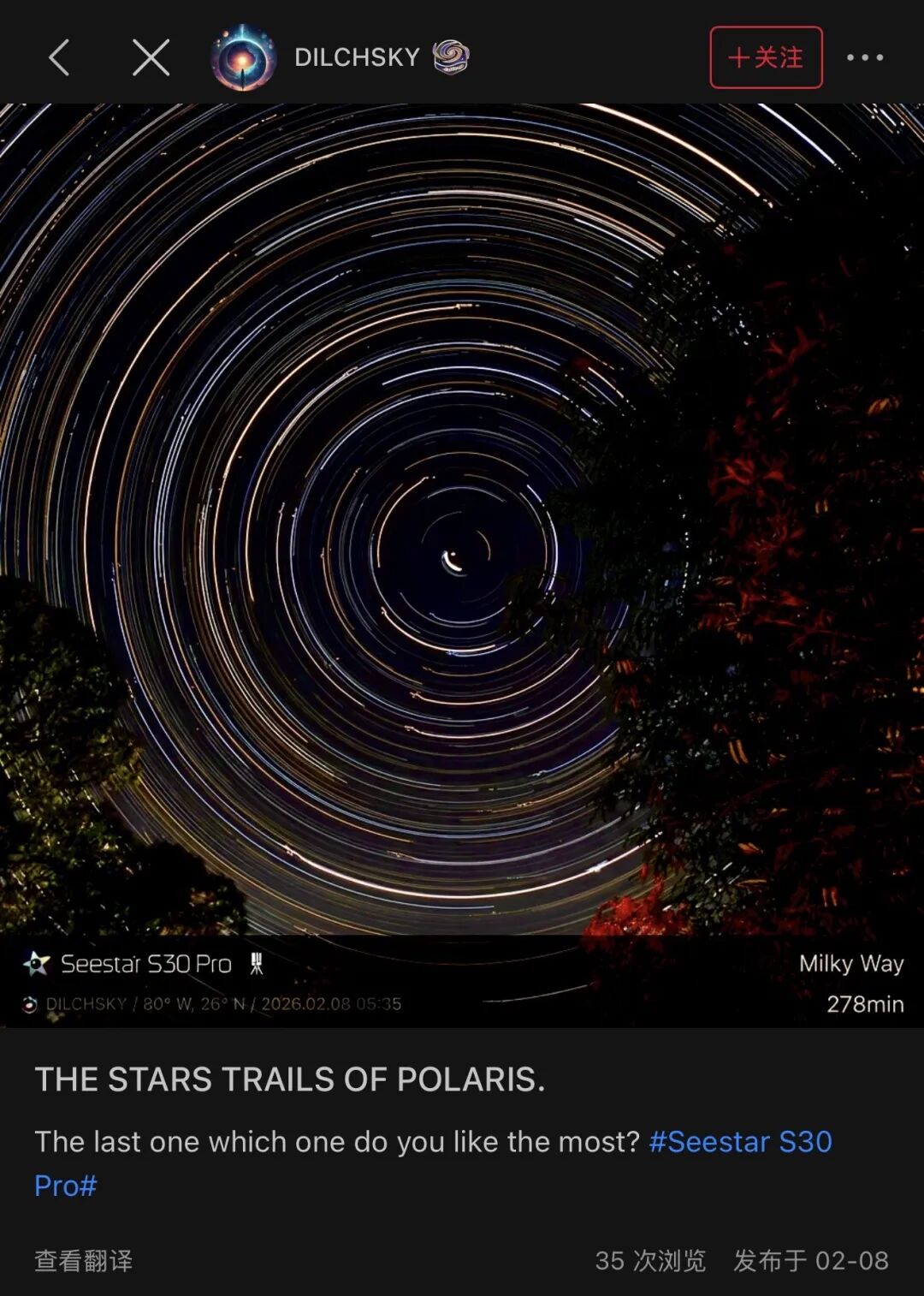
前两天晚上,马斯克在X上转了一个小视频的帖子。视频里的问题是 “Which is the best LLM in the world?” 画面里有两个选项,Grok 和 Others。
在视频里的人始终点不到Grok的按钮,按钮还在不断变小。直到Grok 终于被点到,视频里的「马斯克」开始了搞怪舞蹈。
图片来源:Loopit
这个视频里可以互动起来的产品就是Loopit。
从百川智能离职后,陈炜鹏和李施政创办了涌跃智能。
他们bet的点有3个:
AI Coding 多模态生成融合能吃掉最大的智能增量、通用是最该坚持的产品品味、互动是内容的未来。
虽然AI Coding多模态生成的技术框架探索从没变化,但具体产品设想是模糊的。他们尝试过互动PPT、互动绘本、互动影游,但始终没能同时满足这3个信念。在探索的过程中,他们逐渐将注意力从「用代码提升生产力」,转向「用代码定义可交互的世界」。于是,与行业怎么把一件事做得更高效的主流不同,涌跃智能的产品Loopit 选择了另一个方向。
Loopit 使用页面|图片来源:极客公园
它没有瞄准提升生产力,也不打算做下一个游戏引擎,而是试图回答一个更模糊、也更有想象力的问题——如果内容不只是「被观看」,而是可以被「玩」,会发生什么?
精彩观点:
- 现在的 AI 应用面临的普遍问题是:要么想到做不到,要么做到了也没想象力。。
- 如果内容形态没有逃脱上一个时代的范畴,即使强如Sora,最终也只会沦为既有平台的供给。
- 互动内容是一种更高维的方式,一次性游戏、可以玩的视频等描述都只是其在低维概念的投影
- 在 AI 时代,内容的共识产生会非常快,因为每一个内容的生成上下文都是透明的,这使得 Remix(魔改) 变得极度简单。
- 我们不担心商业化,即使沿用广告模式,互动比观看更能俘获频注意力。
以下是极客公园与涌跃智能团队的对话,经编辑整理。
一、 不是游戏,也不是工具
极客公园: Loopit这款产品的定位是怎么样的?
陈炜鹏: 我们做的Loopit是一款面向 C 端的互动内容产品。在这个内容平台上,每一条内容都是可交互的。它能调用并「接管」手机硬件(如摄像头、麦克风、陀螺仪等权限)。比如,用户手指在屏幕上的位置会实时触发画面亮起或物理反馈,这种创意内容必须依赖硬件交互才能实现。
极客公园:这听起来像是一个通过 vibe Coding 生成的 Mini Game(小游戏)。
陈炜鹏:不完全是游戏。比如一些艺术类交互装置,其底层模态其实是视频,但前端呈现出交互效果。我们想传递的理念是:「让一切变得好玩。」
极客公园:也就是「Make the World Playable」。
陈炜鹏:没错。我们避开「Game」这个词,是因为不想被局限在游戏范畴,而是希望现实生活的一切都能转化为可交互的内容。
极客公园:如果拆解「互动内容平台」这个定义,互动的维度和程度具体该怎么描述?
陈炜鹏:互动的维度涵盖了当前手机硬件能处理的所有范围,比如陀螺仪、摄像头、声音传感器以及常规的点击操作。这些简单的定义可以组合出无限的可能性。
Loopit,意指「循环」。我认为所有的游戏、音乐甚至故事,本质上都是由一个个 Loop 组成的。比如在《星露谷物语》中,播种收割是一个小 Loop,一天的农活是中 Loop,而将手工农场升级为自动农场则是大 Loop。大循环嵌套小循环,就构成了整个世界。短剧的一集是闭环,音乐是节奏循环,这种有限的定义最终能组合出无限的可能。
极客公园:目前主要还是围绕手机终端的交互。
陈炜鹏:对,因为手机是我们的核心分发场景。
极客公园:除了调用硬件传感器,Loopit 相比传统 Web Coding 工具的优化点在哪里?
陈炜鹏:比如用户上传一段视频,Agent 可以自动生成一个「鱼眼镜头滤镜」的程序逻辑套用在视频上,瞬间将其转化为可实时操控的 3D 视角,并可干预互动。
二、AI Coding + 多模态,一次被 AI 技术推动的产品转向
极客公园:依然是 Vibe Coding ?
陈炜鹏:核心是 Vibe Coding 结合多模态生成。我们想打通屏幕与真实世界的界限。
极客公园:具体的创作交互过程是怎样的?需要用户具备专业的逻辑定义能力吗?
陈炜鹏:不需要,完全是基于自然语言的对话式修改。用户不需要设定具体参数,只需描述感受或目标并进行挑选,创意、编程、设计都交给Loopit。
极客公园:那 Loopit 这个产品,从明确形态到今天这个状态用了多久?
陈炜鹏:产品形态明确是 3 个月前,但底层的引擎技术我们磨了 7 个月。
极客公园:过程中最核心的技术难点是什么?毕竟你们磨了 7 个月逻辑。
陈炜鹏:核心难点在于 Code(代码) 与 多模态生成 的深度结合。代码负责保证整个交互过程和底层逻辑,而多模态则负责视觉张力的呈现。这两者在生成过程中相互影响、相互约束,要在这种双重约束下实现通用性并达到优质效果,技术难点很多。
。
极客公园:当时卡点的难点主要是在代码(Code)能力,还是多模态能力上?
陈炜鹏:卡在两者的结合上。我们满意的点在于构建了一个框架,未来不论是 Coding 还是多模态能力的提升,都会成为产品的助力。大家常说大模型应用是水涨船高,而我们这艘船下面,其实有「两片海」。
我是做语言模型的背景,另一位合伙人是做文生视频出身,且做出过国内领先的结果。。
极客公园:对于 Loopit 来说,模型侧的要求是否可以理解为:需要最旗舰的大语言模型提供的 Coding(编程)能力,以及当前顶尖的多模态模型能力?
陈炜鹏:对,我们集成了多种模型,涵盖了文生图、文生视频以及音频生成等多个维度。
极客公园:你们的思路从最初偏向 Pro C 的工具视角,逐渐转向了更广众的 C 端。这中间最重要的变量是这一年 AI Coding 技术的快速进展?
陈炜鹏:多模态和 Coding 技术的进展都非常快。不过我们一直没变的核心是「互动内容引擎」,即 AI Coding 与多模态的结合。至于包装成什么产品、面向什么用户,我们一直在根据技术环境进化。
最初尝试过互动 PPT、互动绘本、AVG(冒险游戏)等内容。随着 AI Coding 技术和多模态模型的进展我们开始向短内容、低门槛的方向迁移,并逐步看到了UGC平台的可能性。
三、重塑平台双边逻辑
极客公园:新平台的产生必须有新交互,从而脱离传统的分发渠道。
陈炜鹏:没错。如果内容模态没有逃脱上一个时代的范畴,即使强如Sora最终也只会沦为既有平台(如 TikTok)的供给。我们坚信互动内容能产生新的交互维度,这种维度是传统短视频平台无法通过增加一个 Tab 就能消化的。
陈炜鹏:基本上,我们现在看到的文生图、文生视频加 Coding(编程)能够组合的所有形态,都可以用这款产品做出来。例如互动故事书、交互式艺术作品,甚至是 Mini Game(小游戏)。
极客公园:所以你们的产品核心是在 App 侧,而不是 Web 端?
陈炜鹏:对,目标和用户不同,自然选择不同的端。
极客公园:目前大多数基于 Web Coding 的 AI 产品都偏向生产力工具,走向了 Pro C(专业消费者)端,重点在于拼 ARR(年度经常性收入)和渗透率。而在普通的 C 端用户层面,最近反而很少有人触碰。我们一直在期待 C 端能出现这种有趣的、真正达到 UGC(用户原创内容)层级的创新。
陈炜鹏:一个新的UGC内容平台产生需要两个条件:一是人人皆可创作(极低门槛);二是新的内容维度。这个新维度必须能提供传统分发渠道所不具备的价值。
极客公园:这种交互带来了很大的个性化。过去用户只能消费被封装死的既有内容,而交互能解锁新的维度,根据用户的心情或操作交付不同的价值。
陈炜鹏:交互是随着技术的解锁而解锁的。目前我们通过 Coding 定义状态机,从而创造出一个自由的交互空间。未来,像谷歌那样的纯 Prompt(提示词)驱动的世界模型会是另一种空间。最终这两者会合并,这只是技术解锁深度的问题。
极客公园:如果最终能一步到位直接生成可交互空间,那确实了不起。不过分步走更务实。
陈炜鹏:我们采取的是分步走的策略。在目前的产品定义里,未来的视频世界模型只是我接入的一个模态。过去多模态靠 Coding 或后台状态驱动,未来可以转为实时驱动。
四、靠 Remix 生长的社区
极客公园:目前内测的反馈如何?用户特征是怎样的?
陈炜鹏:我们正在海外进行内测,几千名用户小规模跑。其中核心创作者约 100 多人,主要由艺术系学生构成。
创作门槛被降到了极低。不少创作者在 TikTok 发布一个高质量伪交互作品大约需要 5 天,但在我们这里,两小时就能做出 5 个。一个 5 分钟的对话轮次就能完成一轮逻辑生成。
极客公园:目前内容池里已有的内容风格,是否会影响现阶段新用户的获取?比如让用户误以为这只是一个特定方向的平台。
陈炜鹏:这本质上是社区「破圈」的过程。我们有非常明确的取舍:不希望被定位为一个游戏平台。游戏市场通常是供大于求的,我们追求的不是纯粹的游戏开发。
极客公园:所以你们更希望呈现的是一种「Playable」(可玩式)的体验?让用户把日常生活中的各种事物变成可玩的交互内容?
陈炜鹏:没错,就是一种「可玩的体验」。
极客公园:在初期,你们核心瞄准的用户群体是哪一类?
陈炜鹏:主要是年轻人,特别是那些极具想象力和创造力的人群。具体来说,包括美术生、艺术生和设计师。从目前观察来看,大学生群体对产品的上手程度非常高,几乎没有门槛。
极客公园:感觉这些种子用户有点像早期 B 站的群体,脑洞很大,想法也比较独特。
陈炜鹏:是的,脑洞非常大。
极客公园:现在的计划是什么?重点打海外市场吗?
陈炜鹏:我们打算国内、国外同步推进。内容属性比较轻量,且没有很强的语言隔阂。下周国内会启动「体验官」招募,先采取邀请制小规模开放创作权限,但所有人都可以下载试玩。
极客公园:国内分享到微信朋友圈的功能打通了吗?
陈炜鹏:打通了,它是以网页链接的形式打开,用户可以在链接里直接进行交互。
五、基于「技术想象力」,构造互动内容产品
极客公园:你看起来不太像典型的 To C 创业者。
陈炜鹏:外界看我职业生涯跨度大,从搜狗做搜索、推荐到 Soul 做社交,但我认为核心逻辑是一脉相承的。在 Soul 期间,我管理过运营和产品,甚至负责过洛丽塔社群的运营,对 18-23 岁的年轻用户群体很有感觉。
极客公园:你之前在 Soul 的经历,对现在的项目有什么启发吗?
陈炜鹏:Soul 对我最大的启发不在于具体的经验,而在于产品价值观。过去我在搜狗做搜索和推荐,是在被定义的市场里把产品做得更好。但在 Soul 期间,我们只关心用户价值和创新体验,这对我做 Loopit 的理念很重要:也就是我们究竟能给用户提供什么样的增量价值和创新体验。
现在的 AI 应用面临的普遍问题是:要么想到做不到,要么做到了也没想象空间。我们要追求的是基于「技术想象力」去构造产品,提供增量。
极客公园:在百川智能的经历呢?
陈炜鹏:在百川负责通用模型训练的经历,加深了我对模型本身的理解。我的判断是: AI 时代核心变量就是技术,脱离技术无法思考产品。只有将技术与产品深度融合,才可能做出让用户尖叫的产品。。
极客公园:在互动内容平台中,社交扮演什么角色?
陈炜鹏:内容本身就具备社交属性。互动天然能产生人与人、人与内容的连接。内容会创造一个「场」,只要场域存在,关系自然会产生。
极客公园:你们的内容深度结合了手机硬件交互。但现在 AI 硬件(如 AI 眼镜、轻量化终端)发展很快,如果未来手机被更简单的终端取代,你们会担心吗?
陈炜鹏:我们完全不担心,甚至非常期待。我们提供的是一套通用框架。手机对我们而言只是「硬件能力的集合」。如果未来出现更先进的智能眼镜,对我们来说只是增加了一个新的 API(接口)和能力维度。只要内容本质上仍通过程序(Coding)实现,硬件的迁移对我们来说是天然友好的。
极客公园:现阶段推荐算法在平台中的比重高吗?
陈炜鹏:随着内容量的积累会更重。
极客公园:如果用一句话来传播 Loopit,你会如何定义?
陈炜鹏:第一,它是一个极具创新性、让人眼前一亮的产品;第二,它就是「可以玩的抖音」,让生活中的一切都变得好玩。
极客公园:用户创作出内容后,他们的动力主要来源于什么?
陈炜鹏:早期是「为爱发电」和获得认同感。过去的内容平台逻辑是:用户创造内容,获得他人追捧,从而产生愉悦感。 在 Loopit,创作动力多了一个维度:创作过程本身的探索性和成就感。这种通过技术实现脑洞的过程,本身就是一种高质量的消费体验。互动循环的核心在于反馈。创作者渴望有人参与互动,而这种良性循环长期发展下去,必然会催生顶部创作者的商业化需求。
关于内容商业化,我观察到一个演进路径:第一阶段是分发效率提升。 早期以推荐系统为主,讨论的是 Feed 流(信息流)的通话效率和广告位密度,核心是解决分发效率。
第二阶段是内容即广告(升维品质)。 到了直播和种草(如小红书)时代,讨论的是品质,即让广告等同于内容,从而提升广告本身的价值。
AI 生成的互动内容让「消费广告」与「消费内容」接近等同。比如海外火爆的「可乐熊」案例,用户在玩的过程中就已经在不知不觉中被植入了品牌概念。这种植入是无感的、潜移默化的,不像直播带货那样仍有明显的广告痕迹。
如果我们的终极目标是去制造一个世界,那么在这个世界里看到的所有广告,都应该是被自然植入其中的。