最近一段时间,Seedance 2.0 几乎成为 AI 视频圈绕不开的名字。
从游戏制作人冯骥的赞叹到美国导演的青睐,中国 AI 视频模型首次在全球范围内实现「物理规律遵循」的断层式领先。
不过,视频生成的爆火只是字节 AI 冰山露出海面的一角。更深层的变革发生在 2 月 14 日——豆包大模型 2.0 的跨代升级,标志着字节正式进入「原生多模态 Agent」时代。
这种升级的核心逻辑,在于字节跳动通过底层能力的全面重构,让 AI 真正实现了从「信息分发」到「任务处理」。不同于部署门槛较高的开源项目,豆包 2.0 将多模态理解、思考长度可调节的逻辑推理以及极其稳定的工具调用能力内化为模型本能。
在字节跳动 CEO 梁汝波提出的「勇攀高峰」年度关键词下,豆包大模型 2.0 正在围绕大规模生产环境的用户体验进行优化,发力成为说一句话就能解决用户问题的端到端 Agent。
提升性能的同时,豆包 2.0 在定价上也颇有性价比——豆包 2.0 Pro(32k)输入仅需 3.2 元/百万 tokens,成本优势远超 GPT 5.2 与 Gemini 3 Pro;而性能反超上代主力的 Lite 版更是将单价压低至 0.6 元。
01
豆包 2.0 的「大脑」升级了什么?
真正决定豆包 2.0 能否承载 Agent 场景的,仍然是底层能力本身。
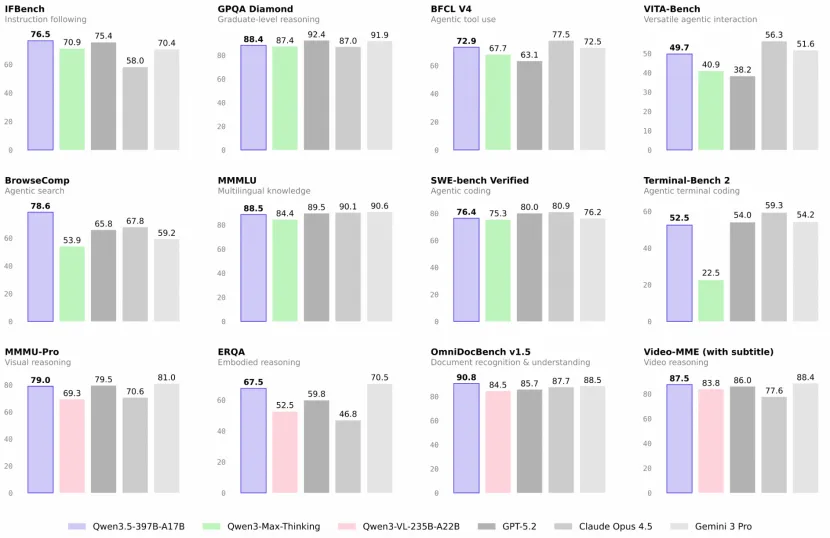
首先是逻辑推理能力的显著提升。在推理与数学等核心评测维度上,豆包 2.0 已经进入与 Gemini 3 Pro 同一梯队的区间。但比榜单更重要的是,它在真实任务中的表现更加稳定:能够完成复杂任务的结构化拆解,建立因果链条,进行多步规划,并在最终输出前进行结果校验。
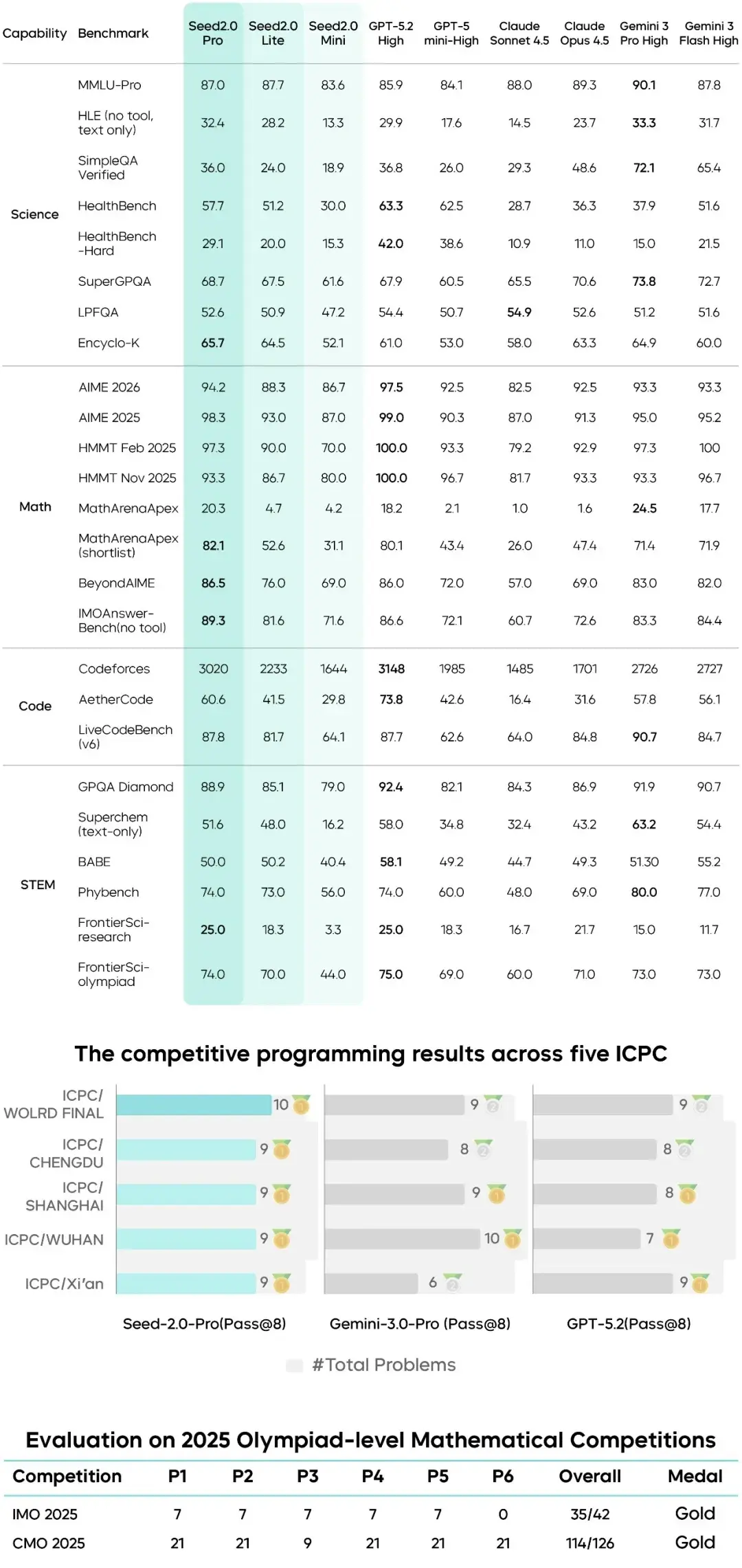
图片来源:字节跳动 Seed
这种能力对 Agent 的意义非常直接。Agent 的本质是「流程更可靠」。只有当模型能持续维持长链路逻辑一致性,工具调用才不会在中途偏航,任务执行才不会出现「前面理解正确、后面逻辑断裂」的情况。换句话说,推理能力的提升,实际上是在为完整任务执行提供一条稳定的骨架。
推理决定了 Agent 的「思考深度」,多模态能力的升级,则决定了它能看见多大的世界。
在豆包 2.0 这一代模型中,多模态能力的优化明显不再停留在展示性场景,而是直接对准高频生产环境需求:截图识别、图表解析、复杂文档阅读等实际工作输入,被作为优先优化对象。这背后的逻辑很现实——企业真实流程里的信息,大量存在于截图、PDF、流程图、设备图纸、报表等非结构化视觉内容中。模型如果无法可靠理解这些输入,就谈不上真正进入生产环节。
在基础识别能力之外,豆包 2.0 在空间理解与运动理解上的提升,也在扩大 Agent 的感知边界。模型不仅能识别图像中「有什么」,还更容易判断「它们之间如何关联、如何运动、如何作用」。
豆包 2.0 的升级是在尝试让模型具备更接近真实世界的输入理解能力。推理能力提供决策结构,多模态感知提供现实世界的上下文,两者叠加,才让 Agent 不再只是处理文本任务,而是能够进入更复杂的生产场景。
当模型既能稳定思考,又能真实感知时,所谓「端到端执行」才真正有了可落地的基础。
02
重塑 Agent
推理能力与多模态感知决定了模型能看多远、想多深,那么真正决定它能否进入企业流程的,是能不能稳定完成一整条任务链。
豆包 2.0 的变化正在这里。
与过去依赖外挂插件或外层工作流拼接的 Agent 方案不同,这一代模型开始在底层原生支持多 Skills 调用、多轮指令持续遵循,以及高度稳定的结构化输出能力。换句话说,工具调用、搜索、格式控制不再是额外补丁,而成为模型推理过程的一部分。
这种差异在长程任务中尤为明显。真实企业流程往往不是一次问答,而是一串连续动作:理解需求、拆解步骤、查询外部信息、调用工具处理数据、生成中间结果、再汇总输出。过去的模型即使单步能力很强,也容易在多轮执行中出现上下文断裂、目标漂移,或在最后输出阶段格式失控。
豆包 2.0 的改进,本质上是在尝试把这条链路变得更可控。其中容易被低估的一点,是「格式输出稳定性」。
在消费级场景里,格式波动只是体验问题;但在企业场景里,格式稳定往往直接决定流程能否自动化衔接。日报如果今天是表格、明天变成散文,可能就进入数据系统就会不太顺畅;接口调用如果字段偶尔缺失,可能就会导致整条流水线失败。因此,稳定输出并不是美观问题,而是生产可用性的前提。
在 Function Call、搜索工具调用与多轮指令遵循能力的增强之外,豆包 2.0 还通过更灵活的上下文管理机制,缓解了模型在复杂任务中的「断片」问题。模型能够在更长的执行周期里保持目标一致性,理解当前步骤在整体流程中的位置,从而减少中途逻辑跑偏或重复执行的情况。这种持续状态感,才是 Agent 真正需要的能力。
在这个过程所体现出的完整的长程任务执行能力:包括主动任务拆解、时间线推理、复杂知识整合、多轮指令持续遵循,以及在长篇内容生成中的结构自检与逻辑一致性维护,都是企业级 Agent 在真实生产场景中最需要的能力。
03
字节的「飞轮」与「野心」
不只在模型能力与应用形态,字节跳动真正试图拉开差距的,反而是在更底层、更长期的 AI 云市场。
火山引擎正在承担一个更关键的角色:把模型能力变成可规模化交付的生产基础设施。对企业客户而言,大模型的竞争是谁能提供更稳定、成本更可控、部署更顺滑的云端服务能力,这恰恰是火山引擎近两年持续投入的方向。
从市场结构看,字节跳动在 AI 云上的优势,是 AI 原生业务带来的真实生产流量。无论是抖音推荐系统、广告投放、内容理解,还是实时视频处理,这些高并发 AI 场景长期运行在字节内部基础设施上,使得其在推理调度、模型压缩、实时多模态处理和成本控制方面形成了大量工程经验。火山引擎把这些原本服务内部业务的能力产品化后,天然更接近企业真实生产环境,而不是实验室式的模型服务。
这种路径也让火山引擎在企业侧的落地速度更快。对于客户来说,选择 AI 云其实是在选择一整套从算力、模型、数据处理到业务工具的组合方案。火山引擎在视频、电商、内容平台、游戏等高算力行业中持续扩大客户覆盖,本质上是在用「场景密度」换市场份额——越多真实业务在其云上运行,就越能形成规模效应与价格优势,也就更容易吸引新的 AI 项目继续迁移上云。
图片来源:视觉中国
这也解释了为什么在豆包大模型 2.0 发布的同时,会反复强调 API 服务、生产环境适配与价格区间。据悉,豆包 2.0 Pro 按「输入长度」区间定价,豆包 2.0 Pro(32k)输入仅需 3.2 元/百万 tokens,成本远低于 GPT 5.2 和 Gemini 3 Pro;而豆包 2.0 Lite 更是将单价压至 0.6 元,在保持低价的同时,综合性能已全面超越上一代主力模型 1.8。
模型只是入口,真正决定企业是否长期使用的,是云平台能否持续提供稳定推理成本与弹性扩展能力。当模型进入大规模调用阶段,云的市场份额就不再只是基础设施之争,而成为 AI 商业化能力的直接体现。
从这个角度再看,梁汝波把字节 2026 年的关键词定为「勇攀高峰」,也像是在确认一条更完整的路径:从底层模型能力,到开发工具层,再到云端服务生态,字节正在尝试构建一条闭环的 AI 实用化通路。而火山引擎所争夺的市场份额,正是这条通路能否真正形成产业壁垒的关键节点。
如果说模型决定了技术高度,那么云的市场占位,才决定了这套能力最终能覆盖多少真实世界。
*头图来源:豆包 AI 生成
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO