在电影《一代宗师》中,叶问在与北派武林的盟主切磋技艺「搭手」前,被「世外高人」账房先生指点:过手如登山,一步一重天。
在主流的理解中,这句话的意思是在告诉观众:切磋本身就是一种进步,不断的进步的过程,就像是在攀登重重高峰一般。
而叶问的答复是:「我就是要见识一下高山」。
2023 年,彼时手机影像领域的竞争,伴随着数款影像旗舰的发布,进入了白热化的阶段,无论是相关的相机模组硬件还是软件技术都迎来了一次重大的迭代浪潮,同时也对「手机摄影」这件事提出了更多新问题:就好像大家同时在攀登一座高峰,但眼前的终点尚未到达,就又看到了另一重高山。
在这种时代背景下诞生的 X100 Ultra,作为 vivo 十年深耕移动影像领域的集大成之作,在发布后颇有「一招定胜负」的意味。即使站在今天回顾,vivo X100 Ultra 的存在,毫无疑问让 vivo 在「全能旗舰」之上的手机影像领域,奠定了「灭霸」的江湖地位,它至今仍然是综合长焦摄影能力最强的旗舰手机。

![]()
vivo X200 Pro | 图片来源:极客公园
作为一名旅拍摄影师,在长期使用过 X100 Ultra 后,我就会觉得它就是我在手机长焦摄影中一直追求的那个「高山」。在知道 X200 Pro 主要的是见识过其实力之后,对接下来的【下放】就不会有任何惊喜。
但实际上我在体验过 X200 Pro 后,见识到的是「另一重山」:如何在保留最原汁原味的「灭霸影像」的同时,最难的是如何也能兼顾好旗舰手机用户的日常需求,不「偏科」。
设计
不仅影像部分脱胎自「灭霸」,X200 Pro 在整体的设计概念上,也与它的前辈高度接近:我们这次拿到 X200 Pro 刚好还是 X100 Ultra 率先引入的同款钛色,无论是边框的拉丝还是相机模组的太阳纹工艺,都透露出 vivo 在高端旗舰系列手机上最终选择的「家族化设计」有着非常的自信。

vivo X200 Pro(左)与 vivo X100 Ultra(右)边框设计对比|图片来源:极客公园
虽然整体 ID 设计相同,但 X200 Pro 由于塞入了 6000mAh 半固态电池,以及保留了同款相机模组,与边框呼应的金属色背板。机身的握持感与观感都在进一步提升的同时突出了专业级产品的属性。同时辅以在相机模组的环状设计的细节处理加强整体调性,同样是 vivo 过去几年在旗舰手机系列上屡试不爽的技法。

![]()
vivo X200 Pro 镜头模组设计 | 图片来源:极客公园
在摄像头装饰圈上,vivo X200 Pro 采用抛光拉丝的工艺与镭雕字符搭配,在原本这套 Ultra 的 ID 设计概念上,展现出一种酷似机械腕表的精密感。同时通过这种代表严谨、高端的意象,向外界传达自己作为「旗舰产品线」的地位。
硬件
相比 Ultra 产品线,Pro 更强调「全能旗舰」的定位,这往往意味着用户需要的是一台「六边形战士」手机。无论是续航、屏幕显示效果,还是性能,都是组成旗舰手机日常使用体验的重要一环。
虽然一直强调下放,但还是需要注意到是 Pro 与 Ultra 两条产品线售价与目标人群上都存在着不小的差异,这些都直接决定了 X200 Pro 不是也不可能是 X100 Ultra 的迭代机型:这一客观事实反而让 X200 Pro 上更具挑战,「堆料」如何打动用户,也是考验手机研发能力「基本功」的重要场景。
X200 Pro 搭载的是联发科今年旗舰 SoC 天玑 9400,配合 6nm 制程工艺的蓝图影像芯片 V3+,同样是 2024 下半年影像旗舰手机中的顶级算力组合:
与过去数年的主流认知相反,手机 SoC 硬件算力如今在计算摄影中正在变得越来越重要,此次 X200 Pro 也因为图像大模型的加入,让充沛的专用算力在影像表现再提升中,更有着不可或缺的重要地位:尤其是在加入 4K60 帧夜景视频超分算法以及专用的舞台录影模式后,都是需要依赖高性能本地计算能力才有可能实现的场景。
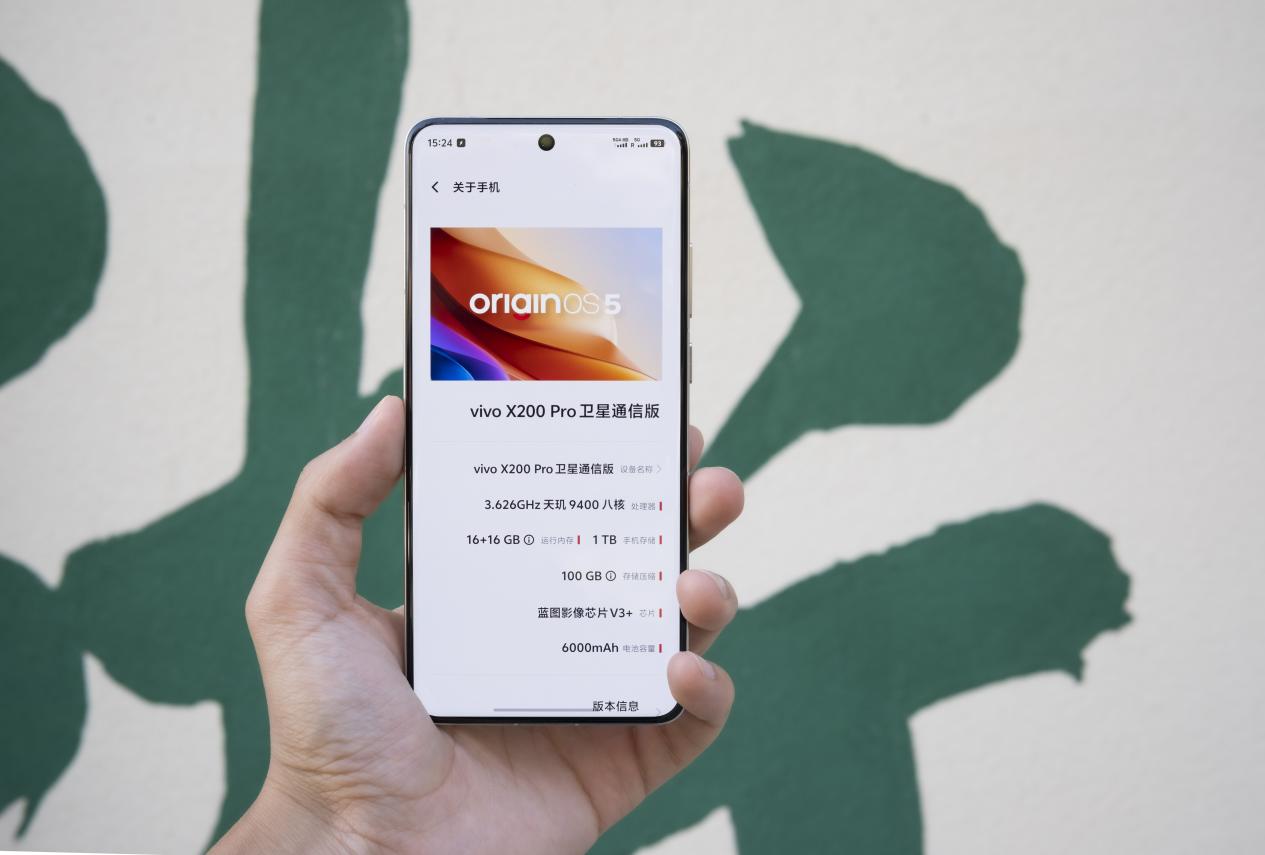
![]()
vivo X200 Pro 硬件配置|图片来源:极客公园
另外,X200 系列首发的公里级无网通信也是功能上带来的新亮点:X200 系列的公里级无网通信作为基于 LoRa(Long Range)扩频技术诞生的产物,能够在完全无网无信号的环境下,可达公里级(对讲可达 2km/广播可达 4km)点对点、远距离的通信,无论是户外露营还是极端天气等情况下,都能派上用场。
「灭霸影像」
前面提到,作为长焦爱好者,我对 X100 Ultra 上搭载的那颗两亿像素蔡司 APO 潜望长焦仍然有难以忘怀的深刻印象:毫不夸张的说,那迄今为止仍然是手机品类中综合表现力最强的长焦镜头,没有之一。
在 X200 Pro 上,作为承载着「灭霸下放」概念的一款手机,相机模组中这张「王炸」被原汁原味的保留了下来;其中不少收获好评颇多的功能:例如 85mm 人像焦段、长焦微距等,以及抗眩光的蔡司 T*镀膜,都被直接继承了下来。

![]()
vivo X200 Pro 影像|图片来源:极客公园
在实际体验中,vivo X200 Pro 在长焦领域的表现与其说是「下放」,不如说是「强化」:同样的景色再用 X100 Pro 的同款长焦硬件上阵,画面中心的锐利度比起 X100 Ultra 甚至有所增强。vivo 还通过新增大模型画质增强技术,
20x 以上提升细节,来获取到更锐利的画面细节。
在超长焦样张等效 200mm 焦段的测试中,引入图像模型的超长焦表现会更加锐利。通过对画面细节边缘的自动计算处理,让观感进一步变得清晰和细腻。
|
|
|


vivo X200 Pro 主摄&等效 200mm 长焦对比|图片来源:极客公园
在长焦众多使用场景中,最能将这颗两亿像素 APO 蔡司长焦性能展现到淋漓尽致的场景,还是 vivo 独有的「舞台模式」:这一模式兴起于众多演唱会 live 爱好者吐槽现场无法带入专业影像器材与长焦镜头,但又希望能记录下舞台上的瞬间,这同样是一个强绑定手机影像超长焦性能的使用场景,因此在 X100 Ultra 首次发布这个模式之后,在小红书上就迅速收获了众多拥趸。
另外 X200 Pro 还引入了对 Live Photo 动态图片的支持:这同样是小红书用户不会陌生的一个功能,在 iOS 支持多年之后,Android 阵营也在这一领域投入了更多资源,未来 vivo X200 系列的动态照片功能,还将支持抖音等平台。
说到城市风光,这一代 X200 Pro 在相机 UI 中的一个显著变化,是在原本收纳众多功能的【更多】菜单迎来了大刀阔斧的改变:原本超过二十个的功能选项减少到了 8 个,取而代之的是名为「风光」的摄影模式。

![]()
vivo X200 Pro 相机中的「更多」菜单|图片来源:极客公园
在这个新整合的「风光」模式中,你其实很难直接找到传统影像旗舰手机常见的各种模式设置,将原本的夜景、月亮、星空、时光慢门等多个模式合并为「风光」模式,一键拍出风光大片。

![]()
全新的【风光】模式中新增的两种摄影风格|图片来源:极客公园
其中新增的两种风光摄影风格,尤其适合在城市风光摄影为主题的场景中使用。

![]()
vivo X200 Pro 长焦风光模式摄影| 图片来源:极客公园
在最强 85mm 超高清人像的基础上,这次还加入了为这颗长焦定制的 135mm 焦段优化:135mm 镜头在人像摄影中有着独特的地位,由于能同时兼顾压缩背景/突出主题,也更接近人眼自然视角,因此被许多摄影师视为经典的人像焦段。实际体验中,135mm 焦段有着不输给原生焦段的画面解析力与对人像细节最重要边缘处理能力。


vivo X200 Pro 85mm 与 135mm 人像对比| 图片来源:极客公园
OriginOS 5
这次 X200 系列在软件上的最大亮点,自然是全系首发 vivo 最新的 OriginOS 5 系统。
OriginOS 每一代都带有当时智能手机用户对手机操作系统迭代需求的影子:从最初的 OriginOS,到 2023 年发布的 OriginOS 4 预览版,其实都是对「下一个时代的手机操作系统应该是什么面貌」这一问题所做出的不同阐释。
OriginOS 4 曾是国内最早一批试水 AI 大模型的移动操作系统的选手,其中包括「端侧+云端混合大模型」、「相册 AI 能力整合」,如今都变成了各家的通用配置,这次 OriginOS5 最大的看点,自然也是在 AI 能力上的进一步深入与进化。
「原子岛」是这次新系统中,最大的亮点之一:虽然在形式上与苹果的「灵动岛」看起来很相似,但实际内核继承自 OriginOS「原子通知」的运行逻辑,能够精准智能地进行信息展示:包括传统的航班/高铁信息,验证码/导航,以及各种借助 AI 意图识别,「原子通知」预判到的你的需求。
例如,如果你在相册拖动图片「上岛」,原子岛就会自动展示出图片可能的分享平台,这样的交互也是打通应用生态的另一种实现方式,例如发朋友圈、小红书等很多原本需要在多个应用之间跳来跳去操作,全程再也无需离开你原本正在使用的 App,效率大幅提升。

![]()
原子岛的快捷分享入口功能 | 图片来源:极客公园
除了一步即达,vivo 还将原子岛做成了一个可以停泊各种信息的「码头」:例如此前包括 OriginOS 在内的主流手机操作系统,在数字健康这件事上都做了「应用使用时间限额」这件事,但都很难将实际的限制时间更进一步展示给用户,而 OriginOS 率先通过原子岛的方式,将时间限额以倒计时的方式直观的展示出来。

![]()
「原子岛」展示应用限额时间|图片来源:极客公园
结语
在 vivo X200 Pro 上,我看到的与其说是「下放」,不如说是沿着前行者已经画出的道路,更进一步。
不只是技术下放,同时也是对新高峰的探索。

![]()
vivo X100 Ultra 与 vivo X200 Pro | 图片来源:极客公园
X200 Pro 集专业级影像和顶级旗舰体验于一身,用 Ultra 级灭霸影像刷新移动影像新体验,具有「一超多能」的旗舰实力。

![]()
相见高山的 vivo X200 Pro,不知道自己,其实已经成为一座高山。